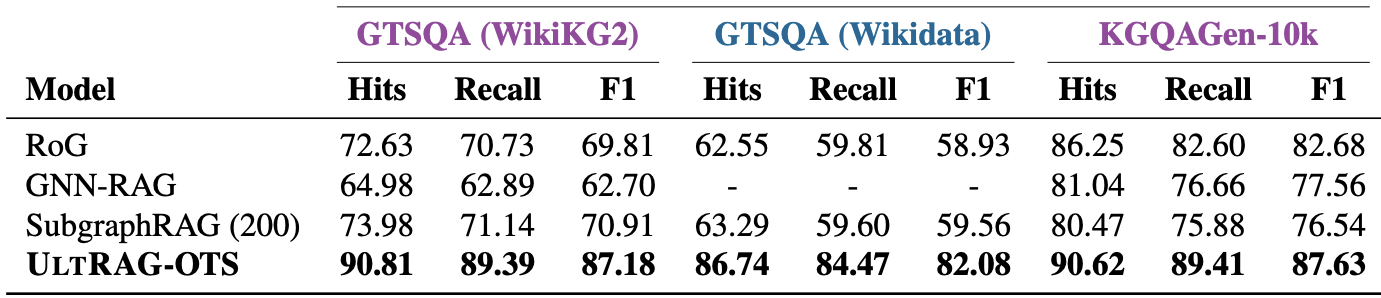
Stochastic Rounding: How randomness helps us build better models
At Graphcore we love compact numeric formats (see Doug's recent post on 1-bit Wonderful Weights for LLMs). Why? Because they are more efficient, in terms of FLOPs/sec and FLOPs/Joule, and we do hate to inconvenience electrons.
This post is on how stochastic rounding (SR) helps us to do more with fewer bits, how we can make SR more efficient, and some things to be careful of when implementing SR.