
Autoregressive Adversarial Post-Training for Real-Time Interactive Video Generation
Real-time interactive video generation requires (1) low latency (ideally frame generation requires a single model evaluation) and (2) the model can only use past frames to generate the current frame (autoregressive generation).
Meanwhile, there exist many models that generate video offline, without real time user input. For example, diffusion models have shown great results in image generation, and naturally, by stacking a fixed number of frames of a video together, e.g. 24fps x 5s = 120 frames, one may train a diffusion model that generates all the frames together. Effectively the temporal dimension becomes just another arbitrary axis in the generated data tensor.
However, diffusion models require multiple denoising steps, which introduces latency. In the case of video, if all frames are generated simultaneously, early video frames are generated together with later ones, effectively allowing them to “see the future”.
The key idea
This work proposes a new method to convert an offline, expensive video diffusion model into a real-time interactive model. While not the first to do so, the authors use a GAN-style generator and discriminator pair and claim to achieve:
- lower latency: 0.16s per frame
- lower compute: 736×416 at 24FPS on a single H100, 1280×720 on 8 x H100
- longer video length: up to 1440 frames, 60s at 24fps

Background
A video may be represented as a tensor $X$ with shape $(T, C, H, W)$: this is first passed through a pretrained 3D VAE yielding $X’$ with smaller shape $(T’, C’, H’, W’)$, where each latent time step equates to four real frames. Subsequent modelling happens in the latent space and at inference time each latent frame may be decoded in real time.
A Video Diffusion transformer model takes 3 inputs:
- text token embeddings
- tokenised noisy video $X’$
- diffusion timestep $t$
and passes this information through transformer layers that include full bidirectional attention over video time steps (past frames attend to future frames) and the output is a tensor of the same shape as $X’$ that may be a denoised image or just the noise component of the input.
Their method
Given a video diffusion model the following recipe can be applied:
-
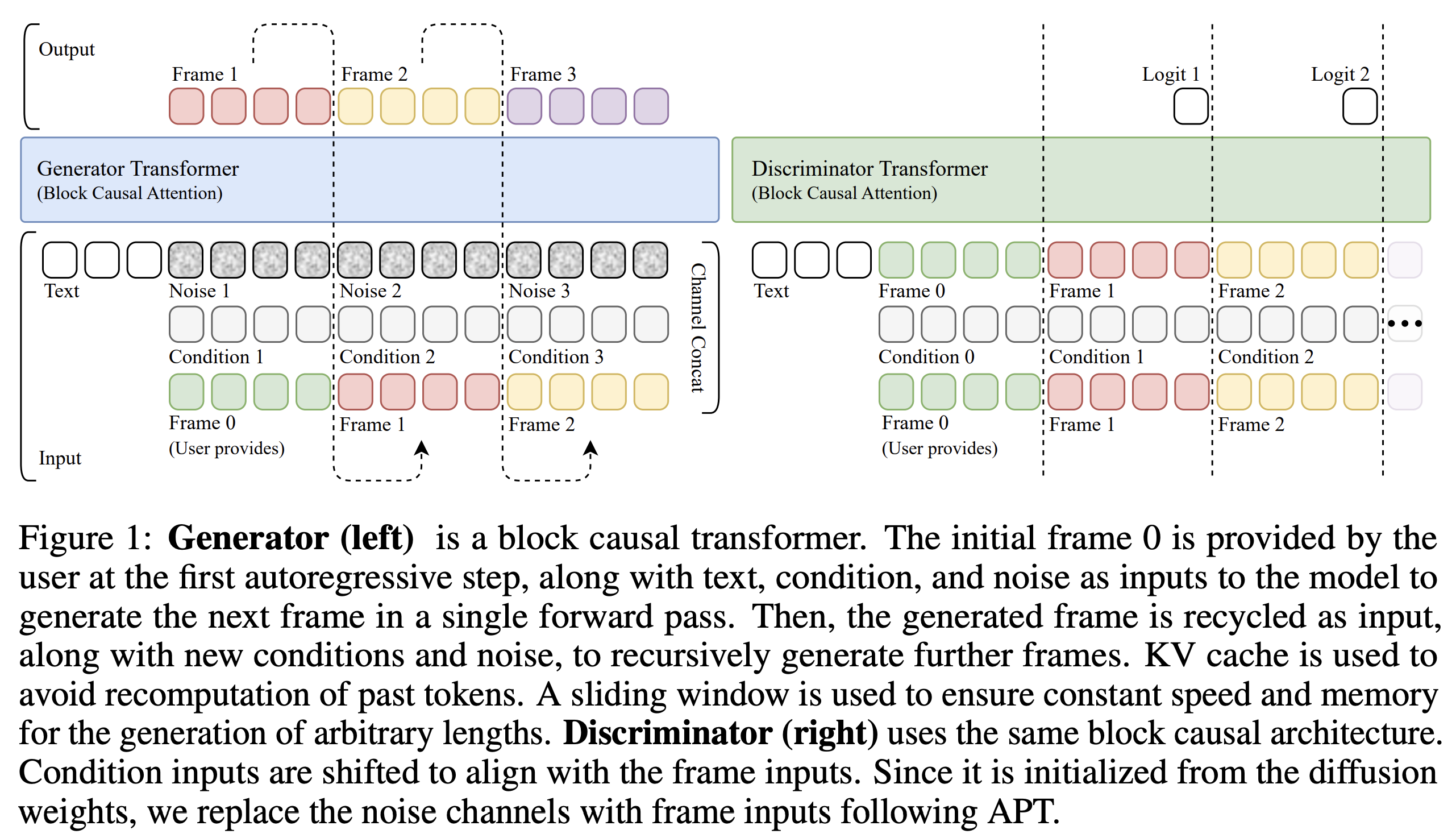
Make the model autoregressive: replace bidirectional attention with causal attention, i.e., each frame can only attend to the text tokens and past frame tokens. This enables the use of KV caching, speeding up inference.
-
Add previous frame as input: the model input for a single (noisy) frame $(1, C’, H’, W’)$ is augmented with the (clean) previous frame through channel concatentation $(1, 2C’, H’, W’)$ — the model is “denoising” the previous frame to the next one.
-
Diffusion adaptation: after making the above changes, one must train the modified architecture using teacher forcing: true frames are used as input to predict true next frame (similar to the standard transformer decoder training).
-
Consistency distillation: the model is trained to predict the final denoised imaged in one-shot, reproducing the result of running multiple denoising steps.
-
Make a discriminator: the discriminator is a new model that uses the same causal architecture as the generator, except that the prediction for each frame is a single logit initialised from the generator after the adaptation in step 3.
-
Train adversarially: the recent R3GAN objective aims to remove the need for the many ad-hoc tricks that GAN methods used to require and is used here to train the generator and discriminator. The generator uses student forcing: starting from one true initial frame, it autoregressively generates each new frame using its own generated previous frame. This reflects inference time usage and significantly reduces error accumulation enabling longer video generation.
Results
The authors take an 8B-parameter pretrained Video Diffusion Transformer model, from which an 8B generator and 8B discriminator are constructed and trained. The main paper contains metrics on VBench-Competition (the qualitative results are shown here).
Qualitative Comparison to Baselines
The authors argue that the student forcing and adversarial training specifically enable longer video generation, which is why baseline methods struggle to generate longer video beyond their training data. However AAPT (bottom) which has a discriminator that can judge any 10 second window of a 60-second video enables the generator to produce longer videos.

Human Poses
Given an initial frame and a user input sequence of human body poses, create a video of a person moving in real time.

Camera Control
Given an initial frame and a user input sequence of camera orientations, generate a video of what the camera would see as it moves.

Takeaways
- Pre-trained offline diffusion models can be converted to online video generators.
- GANs are not dead! Adversarial training can really work and enables longer video generation.




Comments