Would you rather use 1 million \(\times\) 16-bit weights, 4 million \(\times\) 4-bit weights, or even 16 million \(\times\) 1-bit weights?
In joint work between Aleph Alpha Research and Graphcore, we asked this question of LLMs — the answer encouraged us to embrace the wonder ✨ of 1-bit weights, which can outperform 4-bit and 16-bit weights on a fixed weight memory budget.
Knowledge graphs are an efficient and easily verifiable repository of factual information and using knowledge graph queries as a tool for LLMs to improve the factuality of their output is a promising direction.
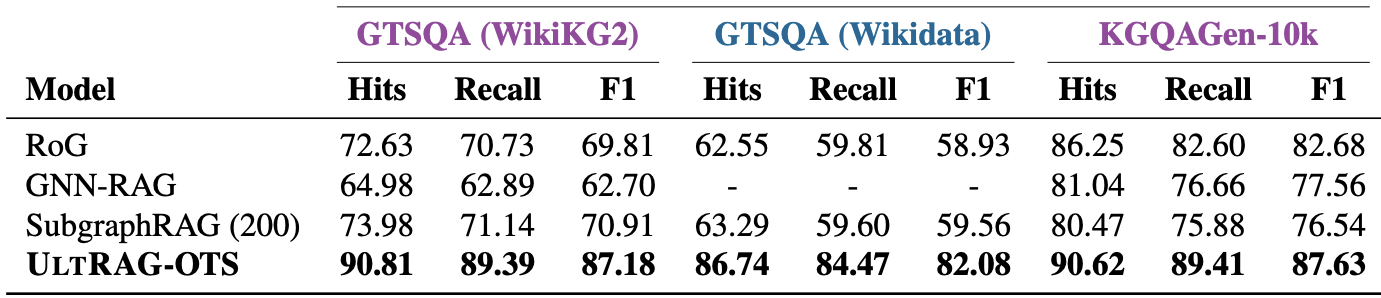
But have you ever wondered how to make query execution work for knowledge graph RAG? "No!"/"Boring!" Let us guess — queries were flawed, knowledge graphs incomplete, results were simply suboptimal. What if we tell you that we have discovered a secret... recipe.
Repurposing existing drugs to treat diseases beyond what they were originally designed for can be a way to identify new disease treatment opportunities. But how do we identify which drugs might affect a given disease? This and similar questions in drug discovery, which require identifying new links between known entities, can be addressed with the help of Knowledge Graphs (KGs), graph-structured repositories of information that represent facts as (head, relation, tail) triples, connecting entities head and tail with an edge that categorizes their relationship. In the biomedical domain, entities can represent drugs and diseases, but also genes, pathways, side effects, etc. KG edges represent interactions like (disease A, associates, gene B), (gene X, upregulates, gene Y) and many more.
Your boss emails you a point in 128-billion-dimensional space. "Llama 3.1 8B," the message reads. "A not-so-large language model in bfloat16. But it's too big. Trim the fat (ASAP)." You open up your toolbox: quantisation, sparsity, distillation.
Quantisation comes first, with two problems. First, you must choose a space smaller than a 128-billion-dimensional binary number for the model to sit in. Second, you need to find a good point in that space. In our recent work on optimal formats for weight quantisation, we've had a crack at the first question.
In this post, we'll learn how to construct optimal formats for known scalar distributions via the "cube root rule". We'll start with a recap of an existing format that claims optimality for the normal distribution. Then we'll explore the cube root rule — a non-intuitive result from the 1950s — and use it to build our own quantisation formats for scaled normal, Laplace and Student's t distributions.
Vision-Language Models (VLMs) allow LLMs to "see", but how do they work? In this post, we'll walk through the model changes needed to turn an LLM into a VLM for inference. To understand the LLM starting point, please see A transformer walk-through with Gemma, as we shall assume that content here.
Problem — Text generation, conditioned on an image: take an RGB image (below) and a short string prompt "What colour shirt is the person to the left of the laptop wearing?", then use an already-trained VLM (Llama-3.2-11B-Vision-Instruct by Meta) to generate an answer to the prompt.
Our role within Graphcore is to help define what the next generation of AI compute systems should look like.
Specialised hardware has been the key driver of the progress of AI over the last decade, and we believe that hardware-aware
AI algorithms and AI-aware hardware developments will continue to be critical to the advancement of this exciting field.
With the rapid advances in the capabilities of large language models (LLMs), there is an increasing need for efficient inference platforms that would enable fast and cheap LLM integration, especially following the release of powerful openly-available models such as Meta's Llama 3.1, Google's Gemma 2, and Mistral 7B.
My colleagues and I always get excited when, every once in a while, deep learning research throws up a fun little maths problem. Our recent work on u-μP does just this, and in a reasonably systematic way, since we need to work out how to compensate for changes in scale (standard deviation) through deep learning ops. In this post and the accompanying notebook, we explore this problem.
The 2024 International Conference on Machine Learning (ICML) was held last month in Vienna, Austria. As one of the "big three" AI conferences, alongside ICLR and NeurIPS, it attracted thousands of AI researchers and practitioners from around the globe. In this post, we highlight some of the topics and papers that piqued our interest.
When ChatGPT launched in 2022, it became evident how powerful the Transformer architecture, when trained on large corpora of text, is for handling natural language processing tasks. The performance of these Large Language Models (LLMs) has been attributed to the in-context learning capabilities that emerge with large-scale training.