
ChipNeMo: Domain-Adapted LLMs for Chip Design
The key idea
The authors describe the practical application of an LLM to assist engineers working on chip design at NVIDIA. They explore the importance of domain adaptation, scale and retrieval augmentation to achieve good performance in three applications: an engineering assistant chatbot, electronic design automation (EDA) script generation and bug summarisation.
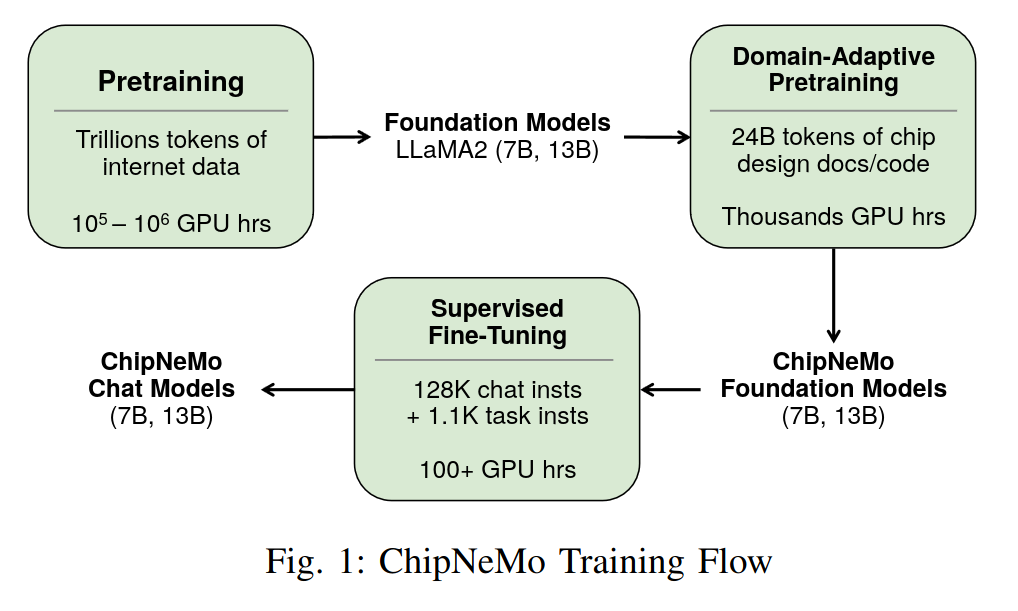
Their method
ChipNeMo takes a pretrained generalist LLM such as LLaMA2, then adapts & fine-tunes the model for better performance on chip design tasks. First, the tokeniser is augmented by extending the byte pair encoding (BPE) vocabulary from a domain-specific tokeniser, going from 32k -> 41k total tokens. The model is fine-tuned on an internal chip design dataset, then fine-tuned for chat on a mixture of open-source general and internal in-domain examples. Finally, retrieval augmentation is used with a domain-adapted retrieval embedding model based on E5.
Results
Results show the utility of domain adaptation and retrieval in boosting task performance, allowing a much smaller domain-adapted model to often outperform a large generalist model.
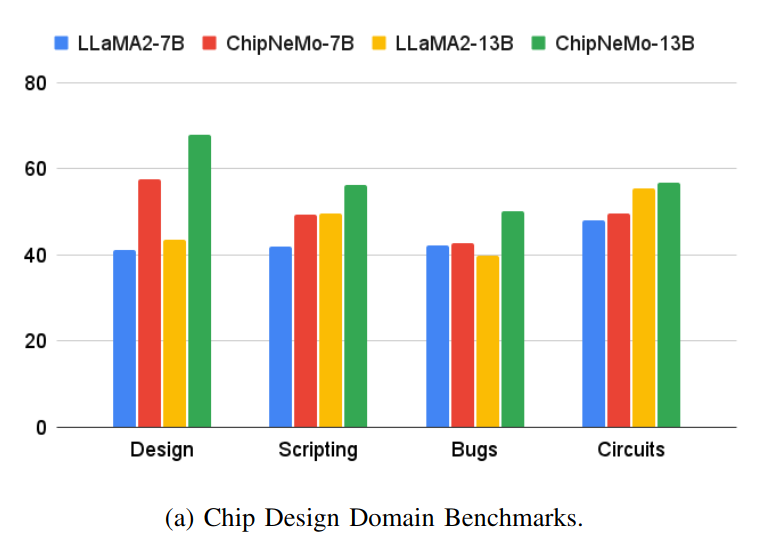
Some interesting points:
- The benefit of domain-adaptation is task-dependent, e.g. for Python coding the larger generalist model (LLaMA2-70b-chat) outperforms ChipNeMo-13b, but vice versa for TCL coding.
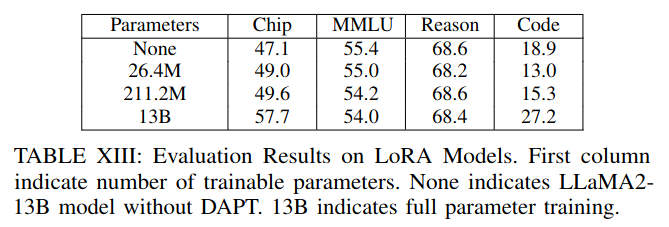
- They found full fine-tuning to outperform LoRA.




Comments