
Constructing Efficient Fact-Storing MLPs for Transformers
The key idea
Even without retrieval-augmented generation, large language models are remarkably good at factual recall. Prior work has shown that this knowledge is largely stored in MLP layers and that models achieve near-optimal facts-per-parameter rates. This paper takes a theory-driven approach to understanding how such fact-storing mechanisms arise by explicitly constructing MLPs as key-value mappings.
Their method
The paper studies a synthetic fact-storage model in which each fact is a key–value pair of embeddings, and recall is implemented by dot-product decoding as in transformers. To analyze how MLPs can realize this mechanism efficiently, the authors explicitly construct MLP weights that act as key–value memories, decomposing the MLP into an encoder and a decoder.
The encoder is a single-hidden-layer gated MLP that maps each key to a low-dimensional code. Keys are randomly grouped into small buckets, and for each bucket a small encoder gadget is constructed that activates only for keys in that group and outputs the corresponding code. This modular design allows many facts to share parameters in a controlled way, which is reminiscent of polysemantic neurons observed in LLMs.
The decoder maps these compressed codes back into the embedding space so that the correct value can be selected. Whether this is possible depends on the geometry of the value embeddings, which the author capture by a decodability measure. Intuitively, if value embeddings are well separated, they can be randomly projected into a much lower dimensional space while approximately preserving their relative dot products, allowing the correct value to still be retrieved from a compressed code.
Results
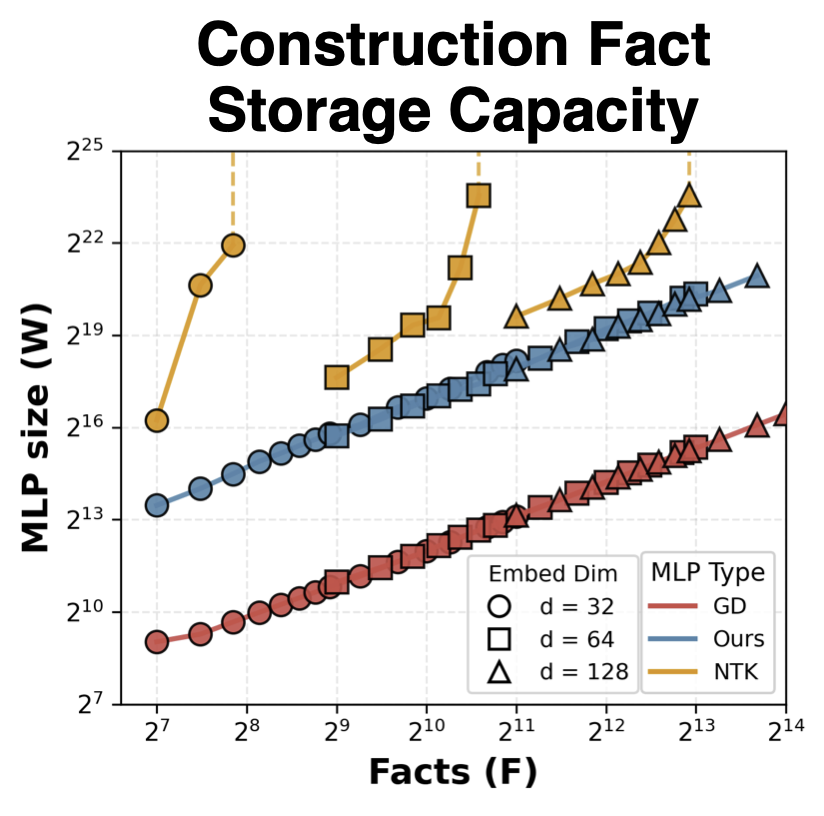
Using synthetic fact-storage experiments, the authors show that their constructed MLPs achieve better facts-per-parameter scaling than previous explicit constructions, and that this scaling matches that observed for gradient-descent-trained MLPs. However, trained MLPs still achieve significantly lower absolute fact-storage cost. The paper also investigates how usable the constructed MLPs are when embedded inside simple one-layer transformers. Here, the authors observe a trade-off between storage capacity and usability: highly compressed MLPs can store many facts, but their outputs are hard to exploit. Finally, they demonstrate a simple form of fact editing by replacing constructed MLP modules.
Takeaways
The authors provides a principled, theory-driven framework for understanding how MLPs can store factual knowledge as key–value mappings, highlighting the role of output embedding geometry as a fundamental bottleneck for fact-storage efficiency. While the constructions are evaluated in synthetic settings and are not directly deployable, they offer useful conceptual guidance for thinking about modular memory, fact editing, and parameter-efficient design in large language models.




Comments