
Fluid: Scaling Autoregressive Text-to-image Generative Models with Continuous Tokens
The key idea
Although scaling autoregressive models has proven remarkably successful in natural language processing, their performance has been lagging behind the dominant denoising diffusion paradigm in text-to-image generation (e.g. Stable Diffusion, Imagen). Building upon their previous work, the authors showcase that the autoregressive transformer architecture can achieve state-of-the-art performance in image generation through two main considerations: using continuous tokens, generated in a random order.
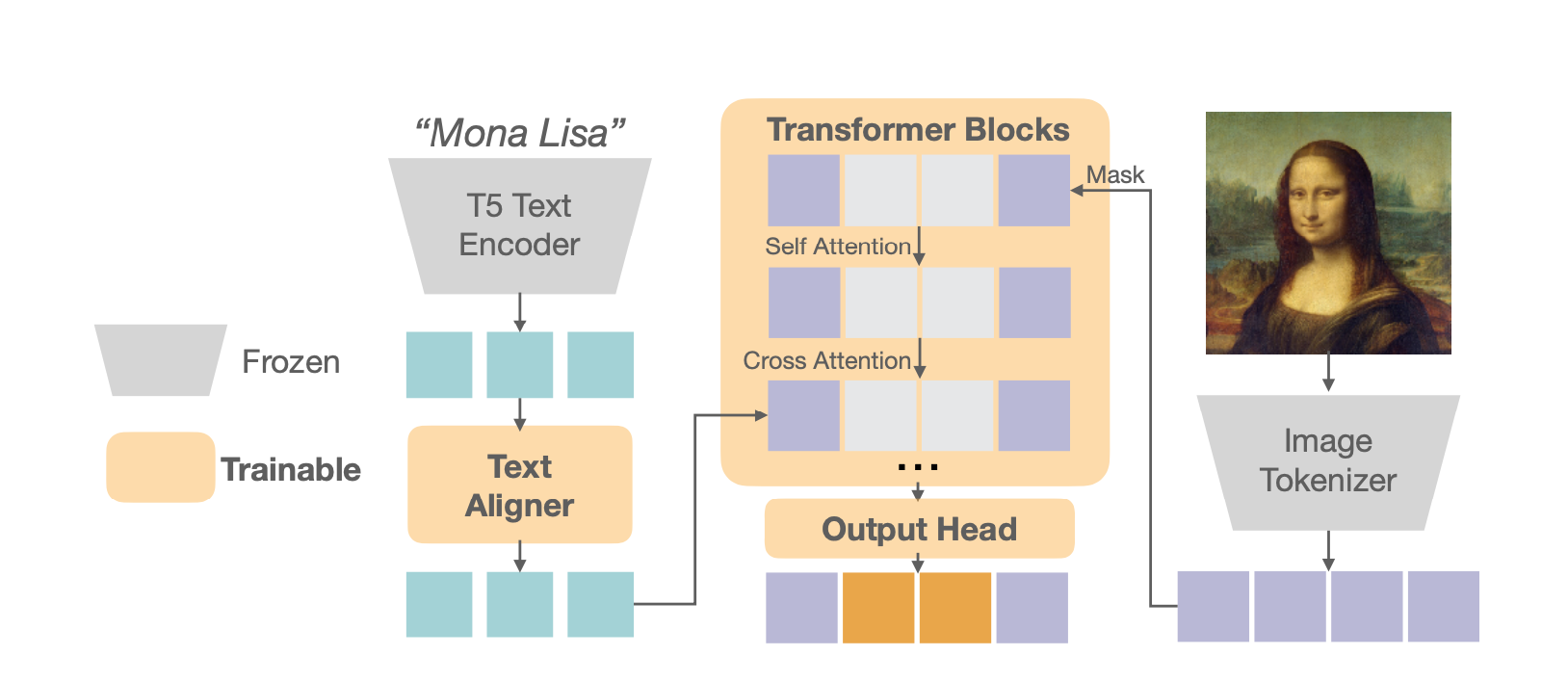
Background
Text-to-image diffusion models have demonstrated groundbreaking capabilities in generating photorealistic images from user prompts. However, these models are generally exceedingly computationally expensive as they require multiple denoising steps to generate a single image, thus motivating the search for more efficient alternatives. At the same time, previous attempts at using autoregressive transformers (such as Parti) have not been able to match the performance of the diffusion models. These models are often used with discrete tokenizers, where the image patches are quantized to a finite vocabulary, so that the cross-entropy loss can be used in the same vein as in language models.
Their method
Following up on their previous work, the authors study two main aspects of the architecture. Firstly, in order to tackle the degradation introduced by discretizing the image patches, the authors consider converting the image into continuous tokens. To accommodate this, instead of the final output of the transformer generating a categorical distribution across the finite vocabulary, the output representation of the final layer is fed into a small six-layer MLP diffusion head. This diffusion process then generates the predicted image token, utilizing the standard diffusion loss during training.
Secondly, the authors consider the effect of generating the image tokens in a raster order vs. a random order. For the former, the tokens are generated sequentially one-by-one from left to right as in a GPT-style transformer. For the latter, tokens are generated in a random order using BERT-style generation, which can facilitate generating multiple tokens at a time, albeit preventing KV caching.
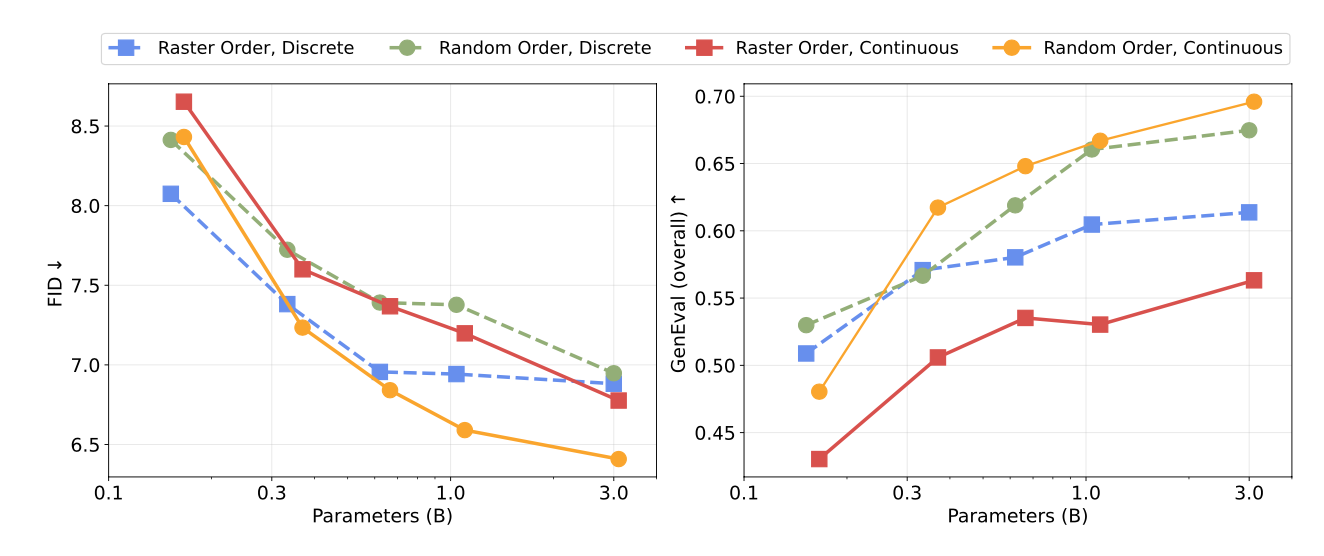
Their results show that the best performance is achieved using continuous tokens generated in a random order, and they scale this architecture to 10.5 billion parameters.
Results
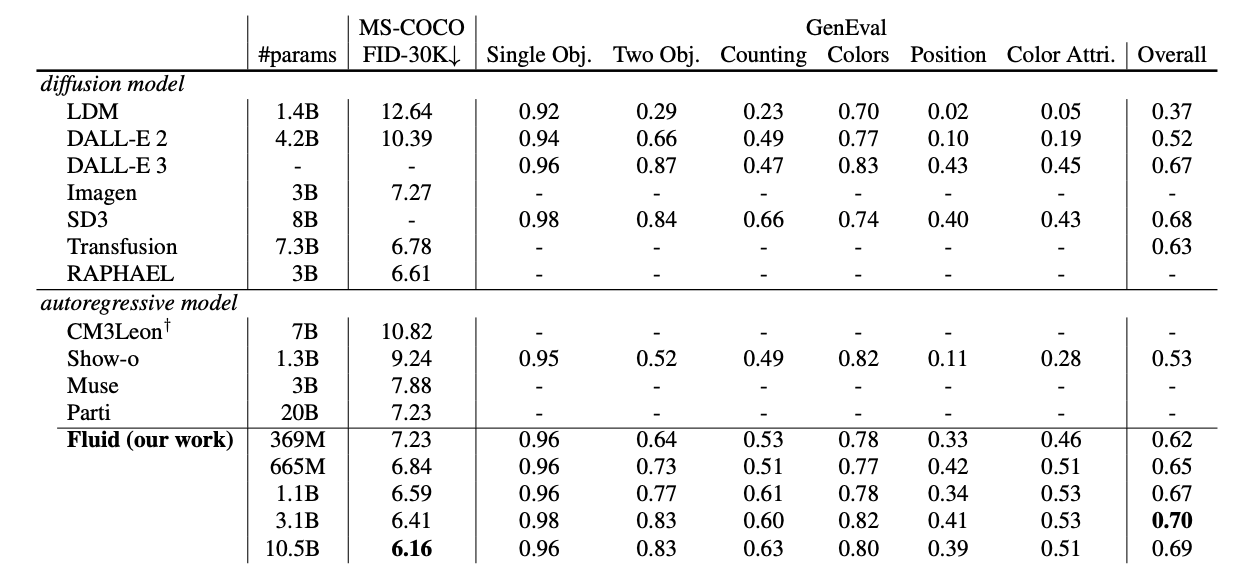
By scaling up the Fluid architecture, the authors were able to achieve state-of-the-art performance, evaluated using zero-shot FID on the MS-COCO dataset as well as GenEval score.
Takeaways
The authors show compelling evidence that using a BERT-style transformer architecture with a lightweight token-generating diffusion head can lead to strong text-to-image results compared to previous state-of-the-art, highlighting a promising alternative to the popular diffusion models.




Comments