
Learning Grouped Lattice Vector Quantizers for Low-Bit LLM Compression
The key idea
The paper introduces grouped lattice vector quantisation (GLVQ), a weight quantisation technique that splits weight tensors into groups, selects a bit width for each group based on a local importance score, compresses their range using a companding nonlinearity, then splits groups into vectors, before rounding to a lattice. The companding function and lattice basis matrix both are trained with a short run on calibration data. This is illustrated below.
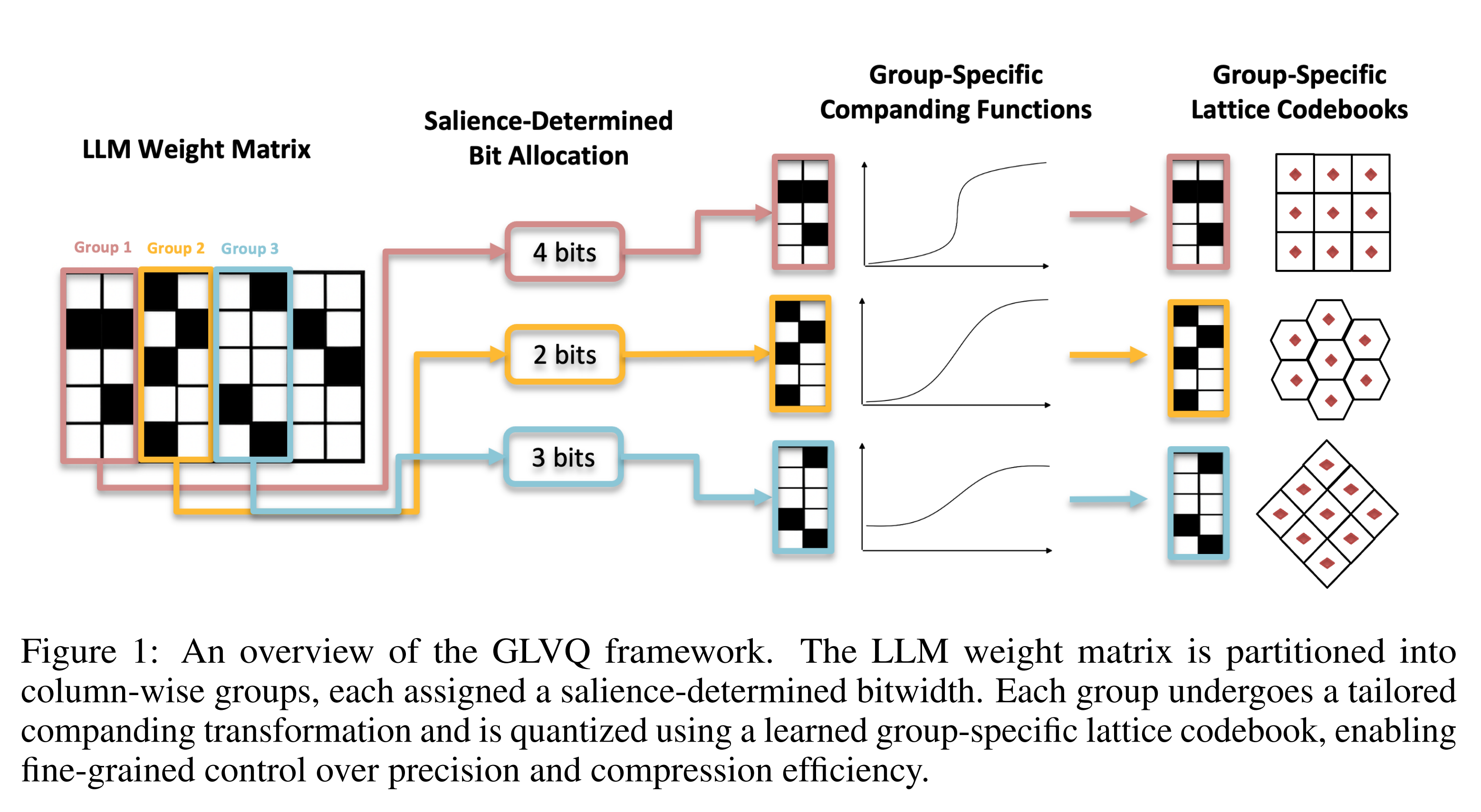
Their method - dequantisation
The dequantisation procedure for a single group of weights starts from low-bit integer indices, reshaped into a matrix multiply (to resolve the point on the lattice) followed by an elementwise nonlinearity (inverse-companding).
I.e. the following pseudocode (using concrete shapes for clarity) for a single vector within a group:
# Given:
# w_indices: int{b}[8] (e.g. int2; b is shared over a group of [4096, 128] weights)
# lattice_G: float[8, 8] (shared over the group)
# mu: float (shared over the group)
# compand_inv: (float, float) -> float
w_tilde = lattice_G @ w_indices
weights = [compand_inv(w, mu) for w in w_tilde]
Their method - quantisation
The quantisation procedure follows four steps:
1. Weight Groups First, divide each weight tensor into large groups (e.g. size $4096 \times 128$) - these groups will be quantised independently, sharing quantiser parameters within each group, and trading off flexibility against overhead.
2. Salience-determined bit allocation Based on activations from calibration data, choose bit-widths per weight group to minimise the local objective $D_{\text{KL}}(\mathrm{Softmax}(W x) \,||\, \mathrm{Softmax}(\hat{W}x))$, where $W$ is the original weight, quantised to $\hat{W}$ and $x$ is a calibration input. E.g. if the average bit width target is 2 bits/param, more sensitive groups might be allocated 3 bits/param, and less sensitive groups 1 bit/param.
3. Companding Since the quantiser in the following step is linear, it is helpful to first compress the range of weights. Use a companding function (elementwise nonlinearity), defined as:
where $\mu > 0$ is a learned parameter per group. For example, for various $\mu$ values, the companding function looks like this:
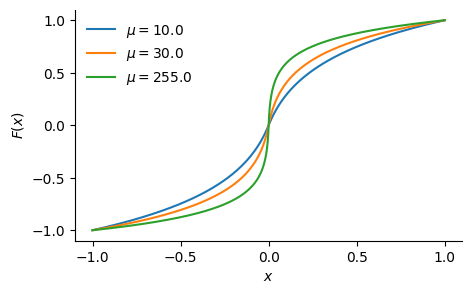
4. Lattice vector quantisation Finally, split each group into vectors (e.g. size 8), and quantise each vector by rounding to the (approximate) nearest point on a learned lattice. The lattice is defined by a basis matrix $G$ (size $8 \times 8$ in this example) as $\{Gz | z\in \text{int}\{b\}^8\}$, which is trained using an alternating scheme: first fixing $G$ and optimising the integer indices using the Babai closest-vector algorithm, then fixing the integer indices and optimising $G$ with gradient descent.
Putting everything together, the quantisation procedure for a group of weights follows:

Results
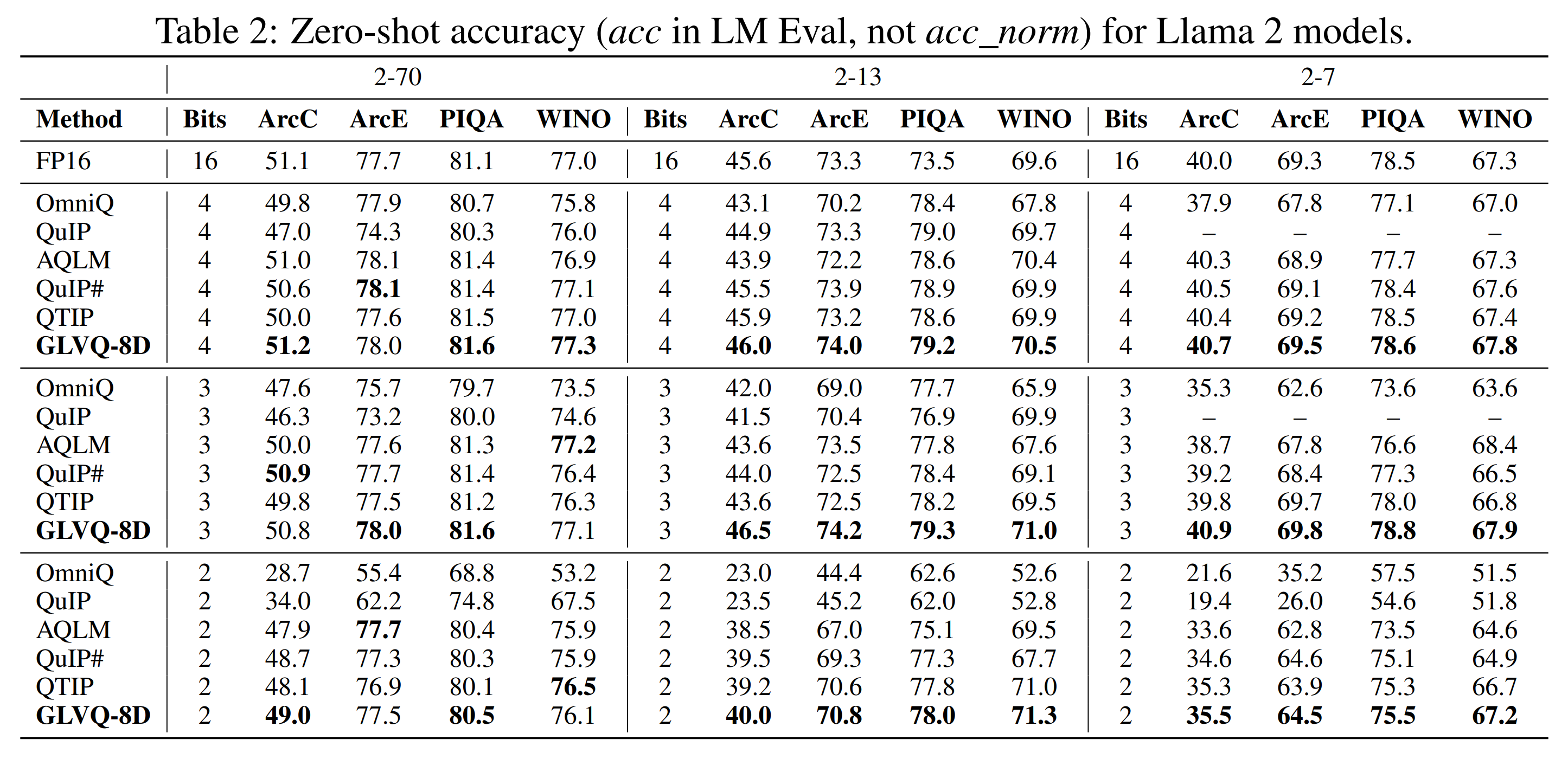
A comparison with other post-training quantisation methods on Llama 2 show competitive results at 2-4 bits/param:
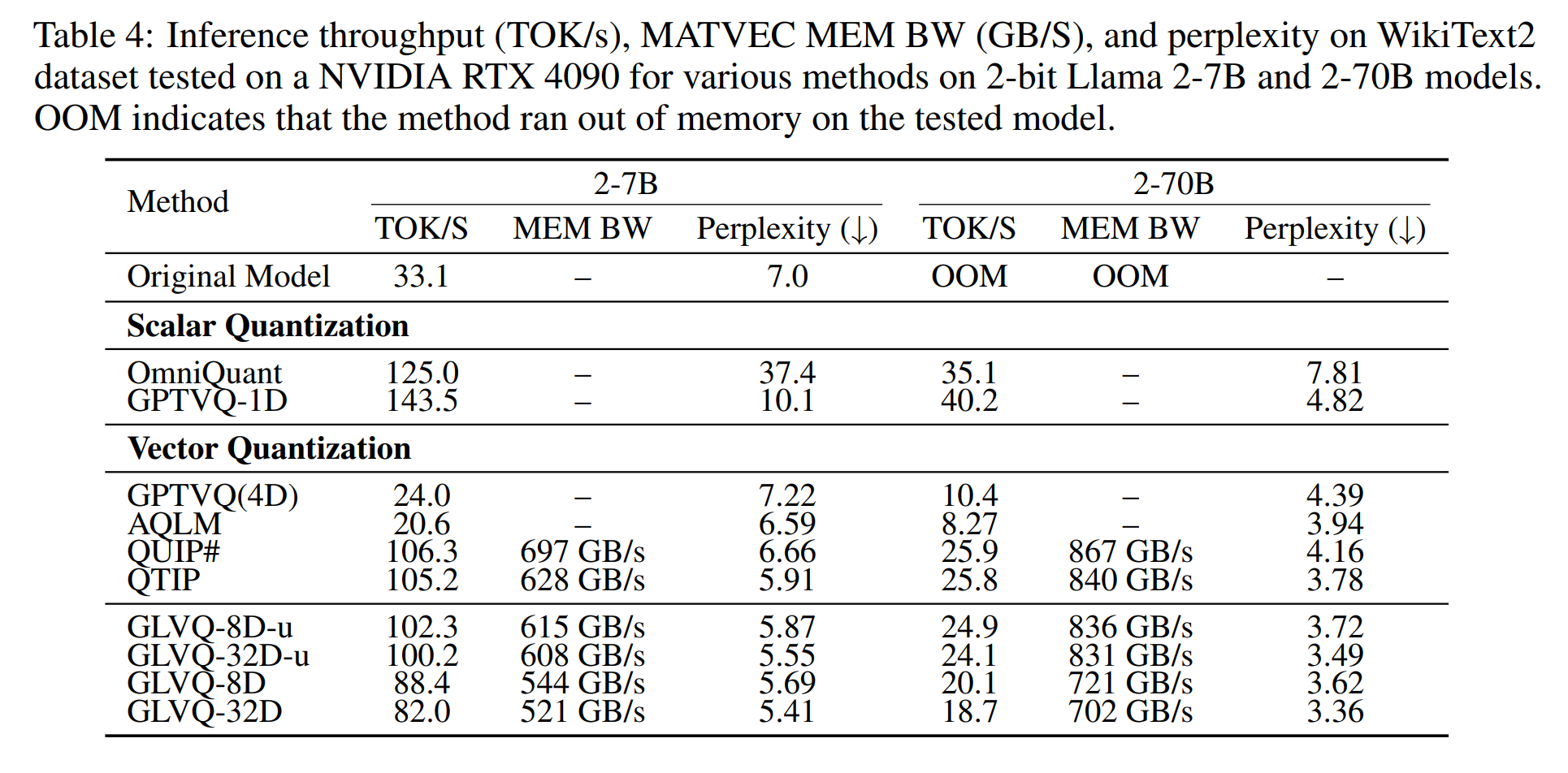
Performance benchmarks also show the memory bandwidth achieved for GLVQ dequantisation before matrix-vector product, as well as overall tok/s benchmarks:
The results are also supported by an ablation of each aspect described in the method section, as well as for more fine-grained design decisions. We omit this here for brevity, although they are a valuable part of the paper.
Takeaways
I really liked this technique and paper — the results seem strong and the performance analysis and ablation are thorough. Like many post-training quantisation papers, which use global calibration data from a forward pass through the model, and local gradient-based optimisation, I would be interested to confirm that this is significantly cheaper than quantisation-aware training, so would like to see PTQ compared against QAT in papers like this.




Comments