
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
The key idea
Language models are generally limited to performing well only on sequence lengths seen during training. Building upon this observation and prior work, this paper introduces a method for greatly extending the context length of pretrained language models using RoPE embeddings through a sequence of relatively inexpensive fine-tuning steps.
Background
Rotary Position Embeddings
Widely used open-source language models such as Mistral-7B and Llama2-7B use rotary position embeddings (RoPE) and are trained on sequences containing up to 4k tokens. Although longer sequences can in theory be easily encoded and processed by the models, the performance tends to quickly deteriorate as the sequences become longer than the ones observed during training.
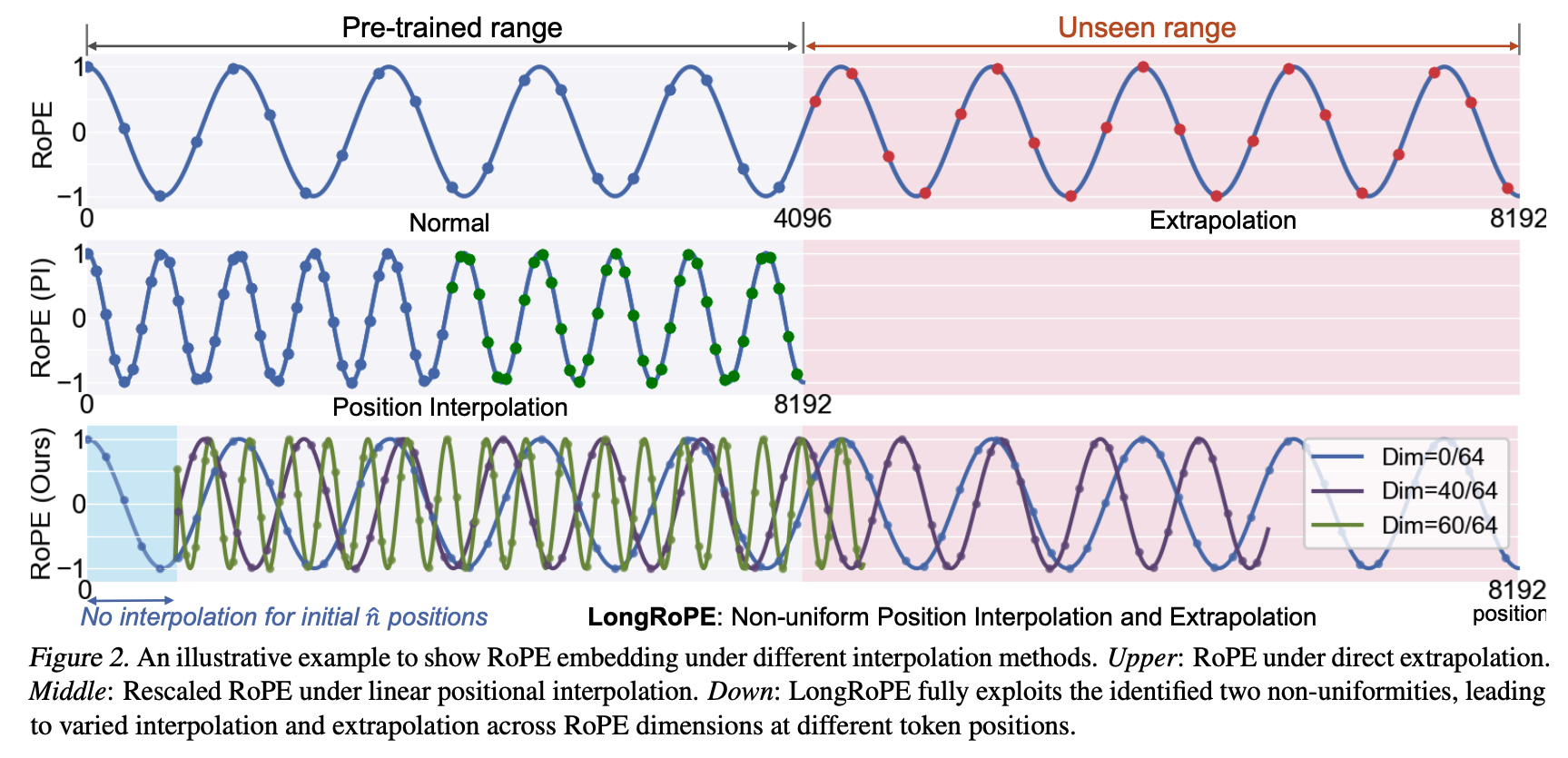
RoPE encodes the positions within the sequence by dividing each (query and key) vector’s dimensions into consecutive pairs and applying a 2D rotation to each pair. The angle rotated is proportional to the position id (ensuring that the query-key dot product is a function of the relative distance between the tokens), and is scaled differently for each dimensional pair: initial dimensions are rotated more (capturing high frequency dependencies), while the latter dimensions are rotated less (lower frequency dependencies).
Prior approaches
Several approaches have been previously proposed to address the issue of generalising past trained sequence lengths:
- The simplest approach is interpolation, i.e., compress the sequence ids to fit within the trained length. This can be problematic as the ids are “squeezed” into a small range, proving especially difficult for the high frequency dimensions.
- “NTK-aware” methods address this by scaling the sequence differently for each RoPE frequency, squeezing the high frequencies less than the lower ones.
- YaRN improves this by further classifying the RoPE frequencies and applying a different approach to each group: high frequency dimensions are not interpolated (not compressed to the training range), low frequencies are only interpolated (always compressed), while the frequencies in between follow a similar scaling rule as the “NTK-aware” method.
Their method
Utilising the observations from YaRN, the authors propose further refinements:
- Find the best scaling factor for each RoPE frequency through an evolutionary search algorithm, instead of the empirically chosen factors in YaRN.
- As initial tokens within the sequence tend to have a large effect on the output (as observed e.g. in StreamingLLM), the authors additionally do not perform the interpolation of RoPE embeddings for an initial token window.
Procedure
The authors note that just finding the best scaling factors without fine-tuning was able to extend the sequence length up to 32k, but incurred performance degradation for longer sequences. Therefore, in order to stretch the context window length to 2M tokens, the authors follow a sequence of steps:
1) Find the appropriate scaling factors for 128k through the evolutionary search, then fine-tune the model using 128k sequence length examples (400 steps). 2) Find the scaling factors for 256k, then fine-tune the model using 256k sequence length examples (600 steps). 3) Find the scaling factors for 2M without fine-tuning. 4) As the extended model can suffer performance degradation on the original sequence lengths, perform an additional scaling factor search for short sequences, then dynamically adjust the factors during inference based on context length.
Model perplexity is used throughout each step to guide the search/fine-tuning.
Results
The authors test the method using three evaluation setups: long-context perplexity, accuracy on a synthetic passkey retrieval task (find a passkey in a long unrelated text), as well as downstream tasks on short-context lengths to evaluate degradation on the original sequence length.
Main observations
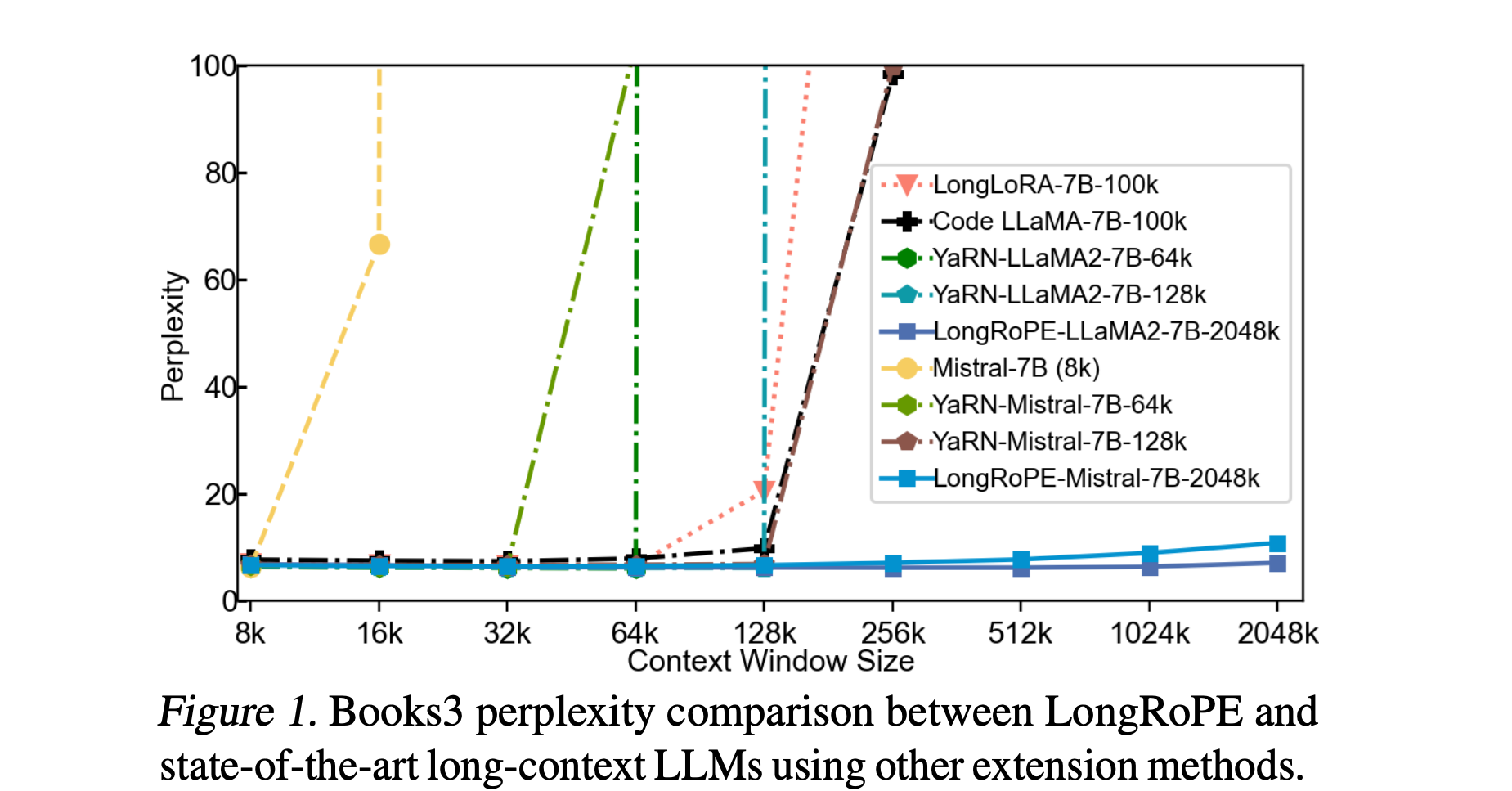
- Perplexity tends to be better compared to other extension methods, and decreases as sequences grow up to 256k.
- Passkey retrieval accuracy is good, falling to about 90% for 1.8M sequence length.
- The performance on original short-context downstream task does degrade, sometimes significantly (46.6% → 39.6% on MMLU with Llama).
Takeaways
As state-of-the-art models such Gemini 1.5 are starting to showcase capabilities to process extremely long sequences, methods for extending the sequence length of short-context language models remain exceedingly important.
The paper provides useful insights into extending context window length of language models, confirming the importance of using different RoPE frequency scaling factors introduced in previous approaches such as YaRN and “NTK-aware” scaling, but noting that the previously used factors are not necessarily optimal. Although the method is able to extend the context window to an impressive 2M tokens length, the model still tends to perform worse on the original shorter sequence lengths, implying that further improvements may be possible.
Understanding the proper steps for robustly extending the context length of models, as well as the comparative pros and cons of such techniques vs retrieval-based approaches, remain essential research questions in the LM community, highlighting the importance of contributions such as LongRoPE.




Comments