
Scalable MatMul-free Language Modeling
The key idea
Building upon BitNet b1.58, which quantises all parameter matrices in a LM into a ternary format, the authors describe a “matmul-free” LM where all forward pass matrix multiplies are ternary.
The authors achieve this by replacing self-attention with a structured-recurrence RNN, which contains only parametric matmuls and elementwise operations, and replace these parametric matmuls with ternary matmuls (shown below).
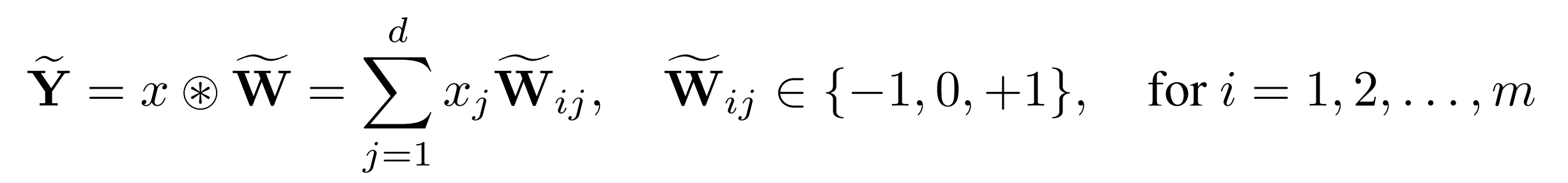
Their method
Following BitNet b1.58, forward-pass weights are quantised to {-1, 0, +1} using absmean quantisation, and activations to int8 using absmax quantisation:

In the backward pass, the straight-through estimator replaces these with the identity function, such that the weight gradient and master weights are maintained in higher precision.
The authors replace attention with the Matmul-free Linear Gated Recurrent Unit (MLGRU),
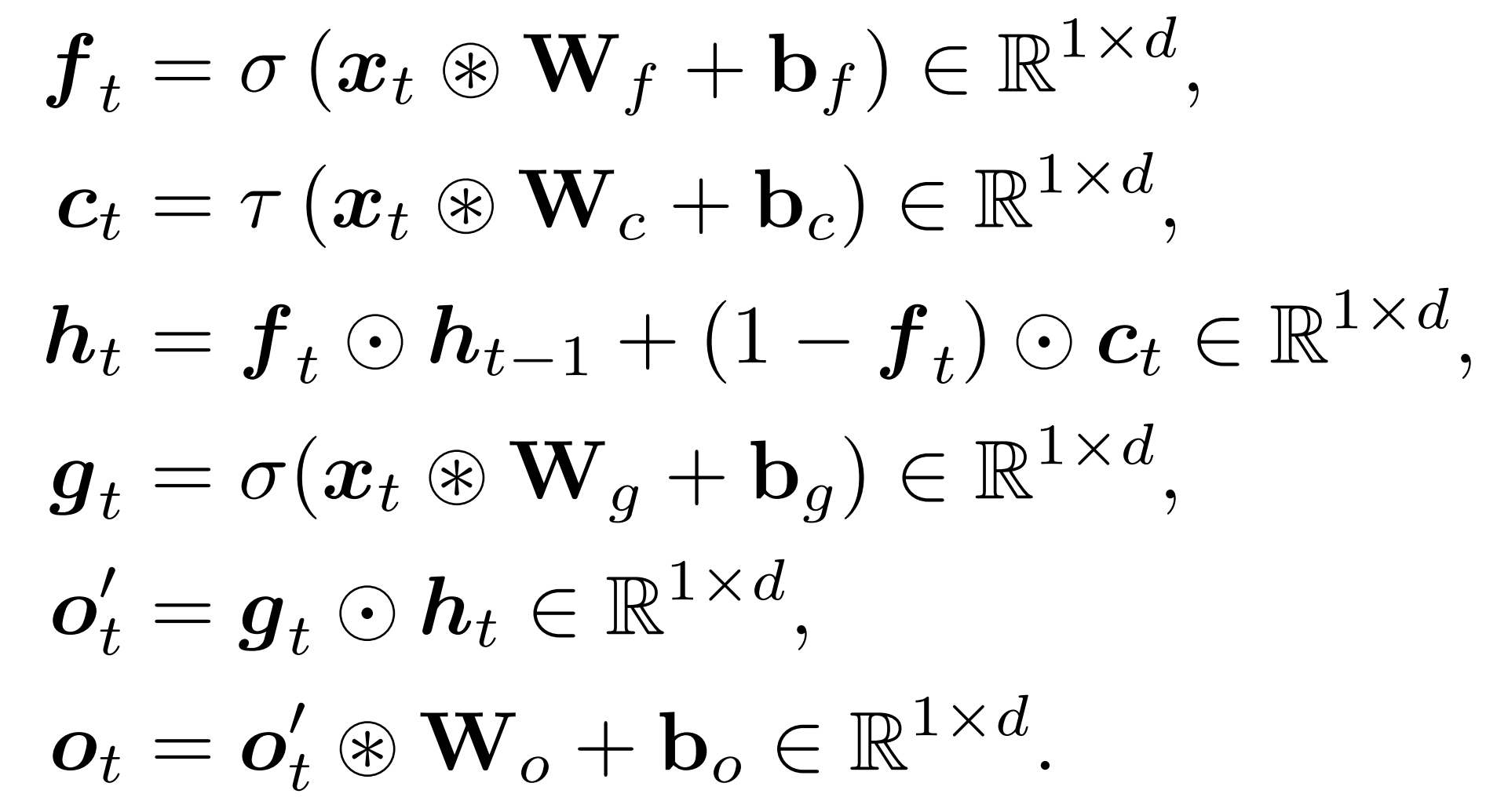
The MLGRU maps a sequence of inputs $\boldsymbol{x}_t$ to a sequence of outputs $\boldsymbol{o}_t$. First, compute three gates: forget gate $\boldsymbol{f}$, output gate $\boldsymbol{g}$ and candidate $\boldsymbol{c}$, which are ternary-weight projections of the input with sigmoid, sigmoid and SiLU nonlinearities respectively. Then use the forget gate to interpolate between the previous hidden state $\boldsymbol{h}$ and the candidate. Finally, use the output gate to mask the hidden state before projecting via a final ternary matmul.
FPGA implementation
While ternary weights provide an advantage of reducing memory transfers when running on modern ML hardware, they are not supported by matrix compute units, so the energy benefits of ternary quantisation are not realised. To illustrate the potential of the matmul-free LM, the authors implement a custom FPGA accelerator in SystemVerilog, implementing a small special-purpose instruction set. They deploy the RTL on a D5005 Stratix 10, which runs a width-512 single-layer forward pass in 43 ms.
While the authors acknowledge that this is a limited and preliminary result, their extrapolations to incorporate bursting over the DDR4 interface, using vendor IP and adding pipelining show promise (24 tokens/s of a 1.3B model at 13 W). The number of cores may also be increased, yielding higher throughput (and power).
Results
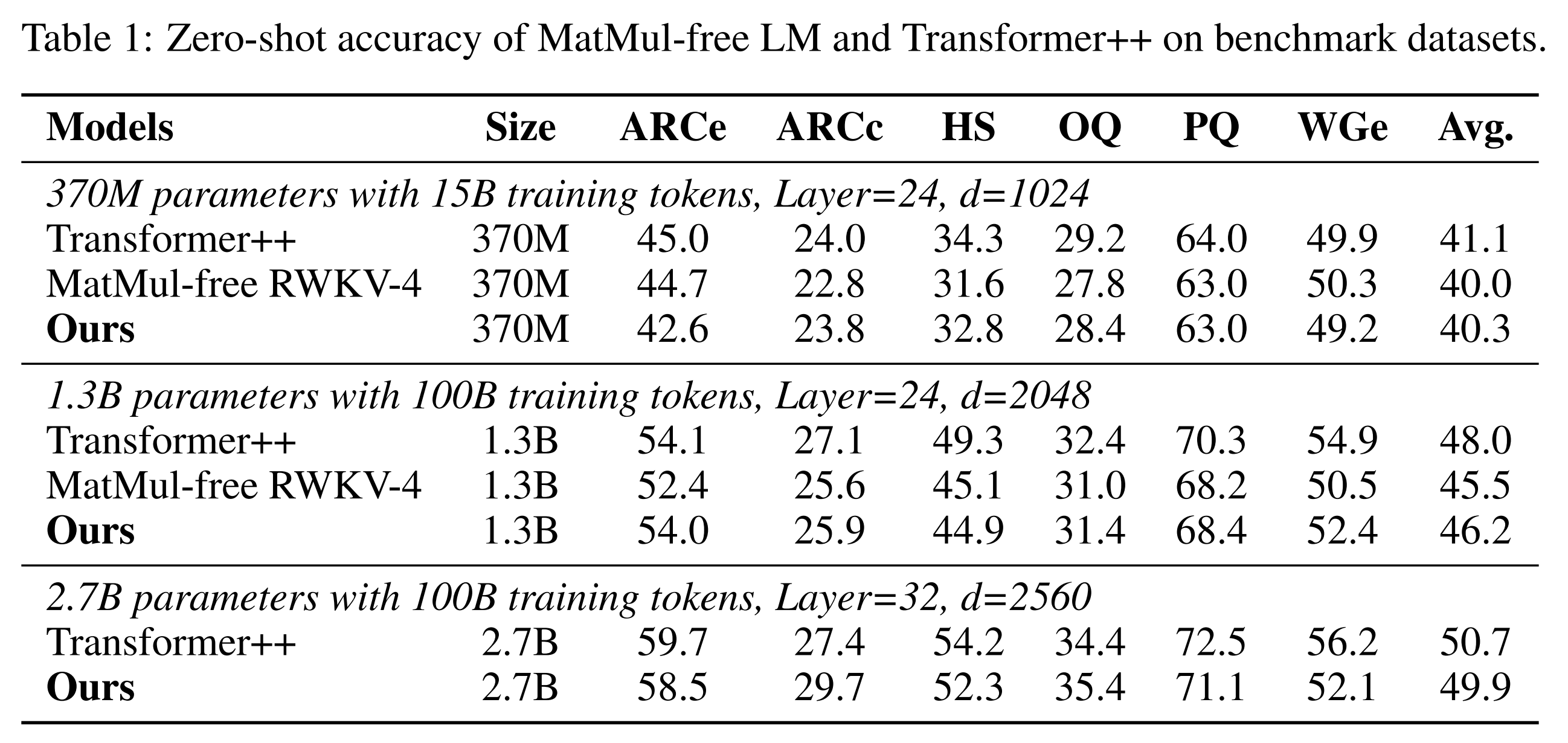
Results compare well against a Transformer++ baseline when trained on SlimPajama. The limited training duration makes it hard to compare the baselines with state-of-the-art LMs trained on this dataset, but the baseline is competitive with that of BitNet b1.58.
Takeaways
We’re excited to see this line of work continue, as it challenges our preconceptions regarding continuous optimisation in deep learning and offers the promise of reaching new levels of practical efficiency.



Comments