
Better & Faster Large Language Models via Multi-token Prediction
The key idea
Large language models are usually trained using the next-token prediction loss. The authors propose training the model to predict multiple tokens at a time instead, while still generating a single token at a time at inference as usual. By training models up to 13B parameters in size, they show that this can lead to models with better performance, particularly at coding tasks.
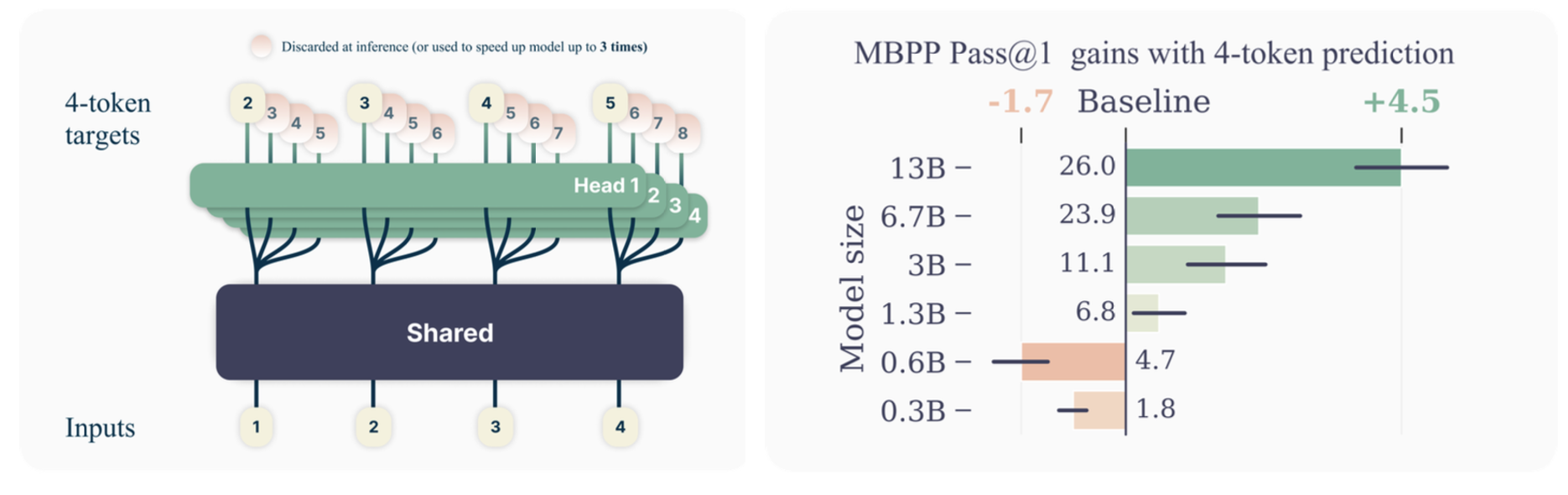
Their method
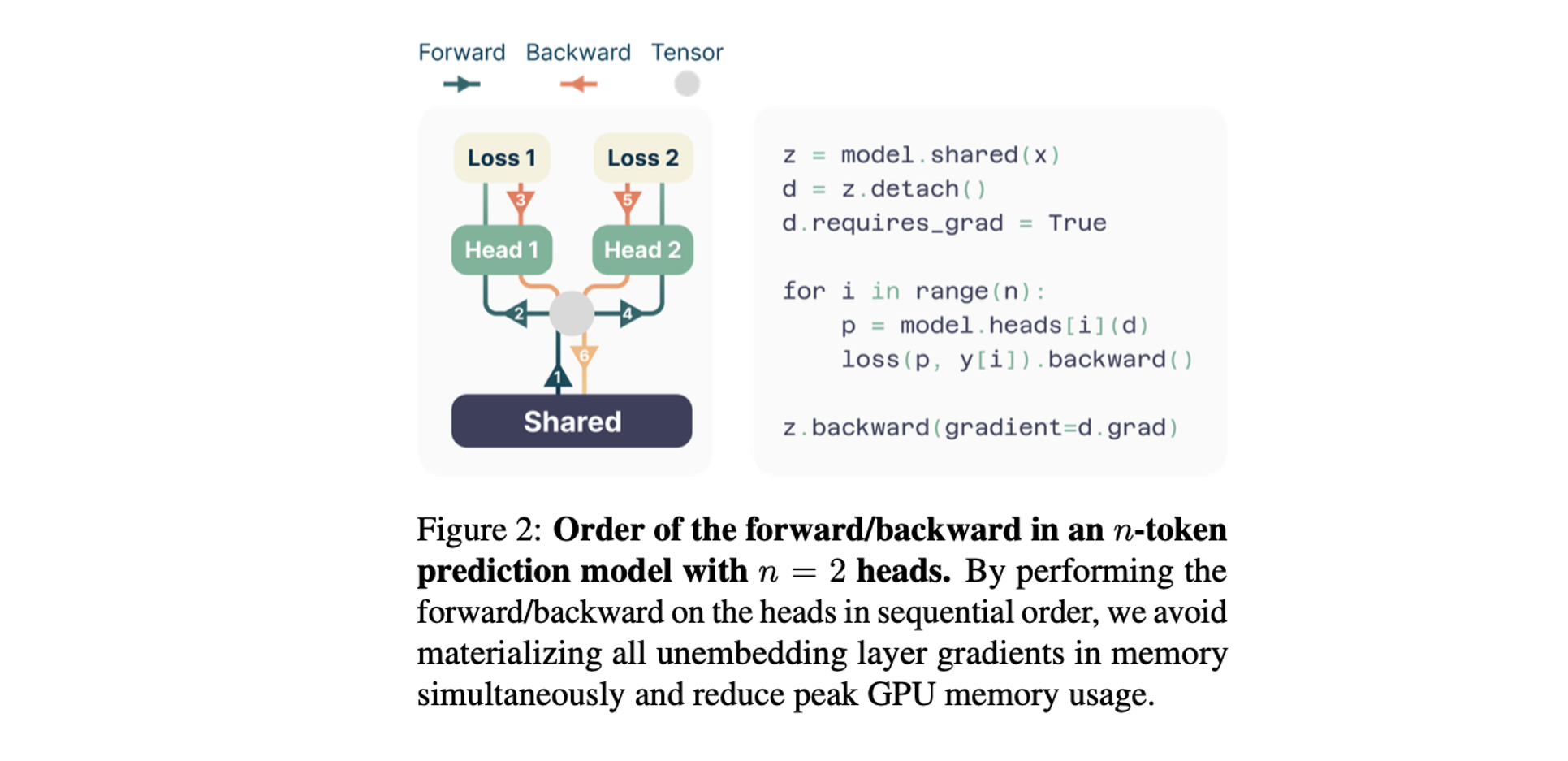
In order to enable multi-token prediction, the authors propose a simple modification to the standard transformer architecture. The final output embedding is fed into $n$ parallel output heads, each a single standard transformer layer. This effectively means that the final transformer layer is replaced by $n$ parallel transformer layers. The outputs of each head are then passed through a shared unembedding projection, generating a probability distribution over the whole vocabulary for each head. During training, each head is then trained to predict one of the next $n$ tokens for each training example. In order to minimise maximum memory usage during training, the forward/backward passes on each head are performed sequentially (Figure 2).
During inference, all but the output of the first head are discarded, and tokens are generated one-by-one as with the standard transformer architecture. However, multiple-token prediction can be used to speed-up inference using self-speculative decoding, i.e. by using the $n$ generated tokens as an initial sequence draft, and validating the sequence with just the next-token head in parallel.
Results
- Improvement was only observed at scale - improvements were strongest for the largest models.
- Observed 3x speedup using speculative decoding with 7B 4-token prediction model.
- Optimal $n$ was empirically found to be 4 for token-based models, and 8 for byte-based models.
- Unlike coding tasks, on natural language tasks the performance does degrade compared to the next-token baseline.
Takeaways
The results of the paper are promising, as they show multi-token prediction can indeed lead to improved performance at scale, particularly at coding tasks, while at the same time providing a more suitable drafting model for speculative-sampling inference. The results hint at the possible benefits of teaching the model to “plan ahead” compared to the standard next-token prediction, and may lead to exciting alternatives to the widely-adopted token-by-token generation.




Comments