
Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach
The key idea
This paper from Google DeepMind attempts to answer the question of which is better - long context LLMs (LC) or retrieval augmented generation (RAG)? For state-of-the-art LLMs they find that LC outperforms RAG, albeit at a larger computational cost due to the quadratic complexity of attention. However, they find that for most queries, both RAG and LC generate identical predictions. Motivated by this observation, the authors propose a method to route queries to RAG or LC, reducing the cost of inference while maintaining task performance comparable to LC.
Background
An emergent behaviour in LLMs is in-context learning, in which models can retrieve and learn from information present in its context. This behaviour allows models to learn from new information not seen in its training data, without requiring fine-tuning. However, the attention operation present in LLMs has a cost that scales quadaratically with the length of the sequence, and therefore increasing the amount of context may lead to slower performance. Retrieval Augmented Generation (RAG) can alleviate some of this cost by only retrieving a subset of relevant documents/information, which is added to the prompt before the inference process begins. This permits shorter, cheaper sequence lengths, but does not allow the model to see all avaialable context during inference, and relies on a quality retrieval method to ensure that the relevant documents have been retrieved.
Their method
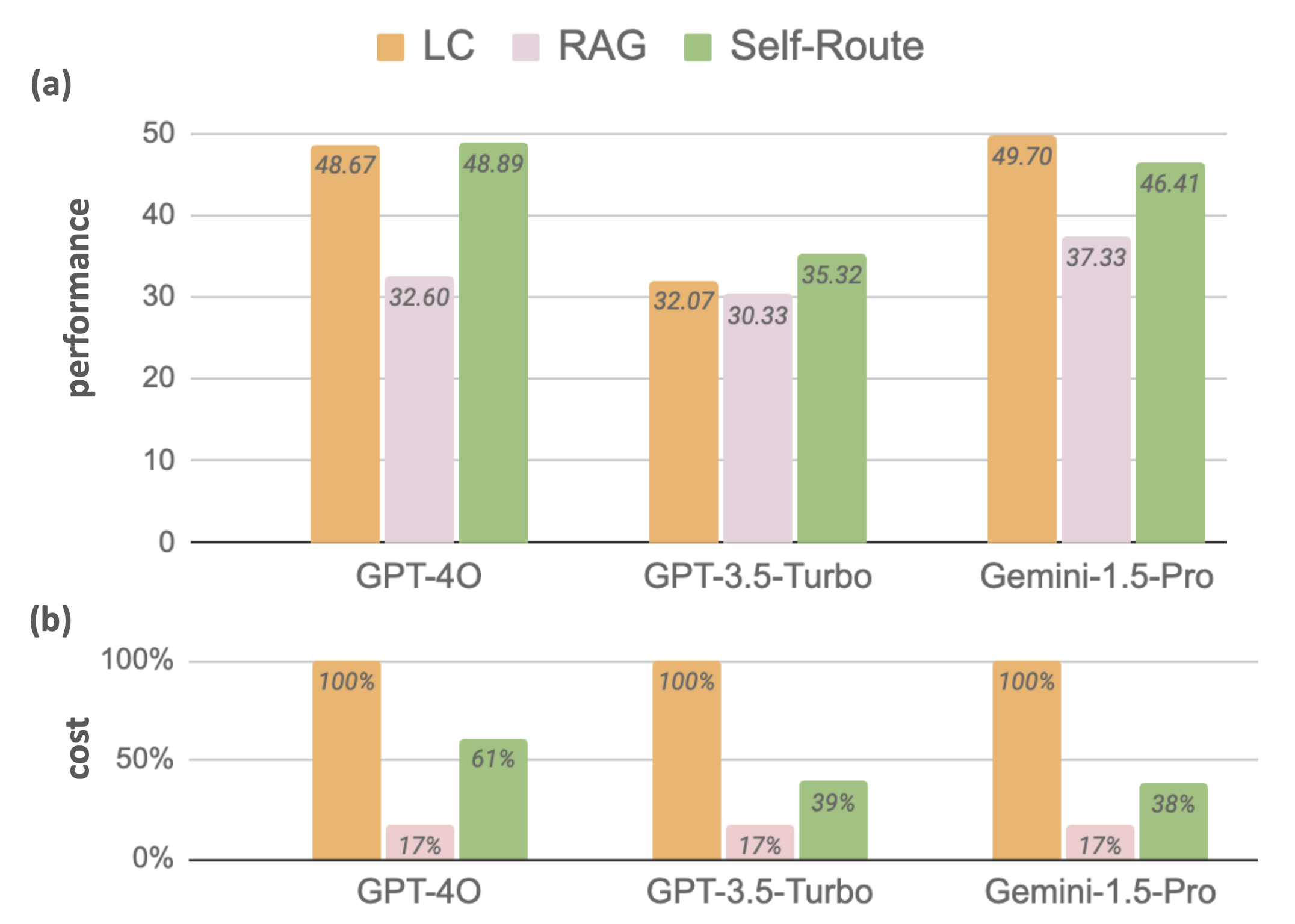
The authors benchmarked both LC and RAG approaches on a variety of NLP tasks and state-of-the-art LLMs, including Gemini-1.5-Pro, GPT-4O and GPT-3.5-Turbo, which support context lengths of 1M, 128k and 16k tokens respectively. The results found that in general, LC outperforms RAG, except when using datasets from $\infty\text{Bench}$ (where RAG outperforms LC for GPT-3.5-Turbo, likely due to the model’s limited context window). These results differ from previous work comparing the two strategies, but the authors argue this is due to their use of stronger LLMs and longer contexts in their experiments.
One observation they noted was that for 60% of queries, RAG and LC generate the same prediction (ignoring whether the prediction is correct or not):
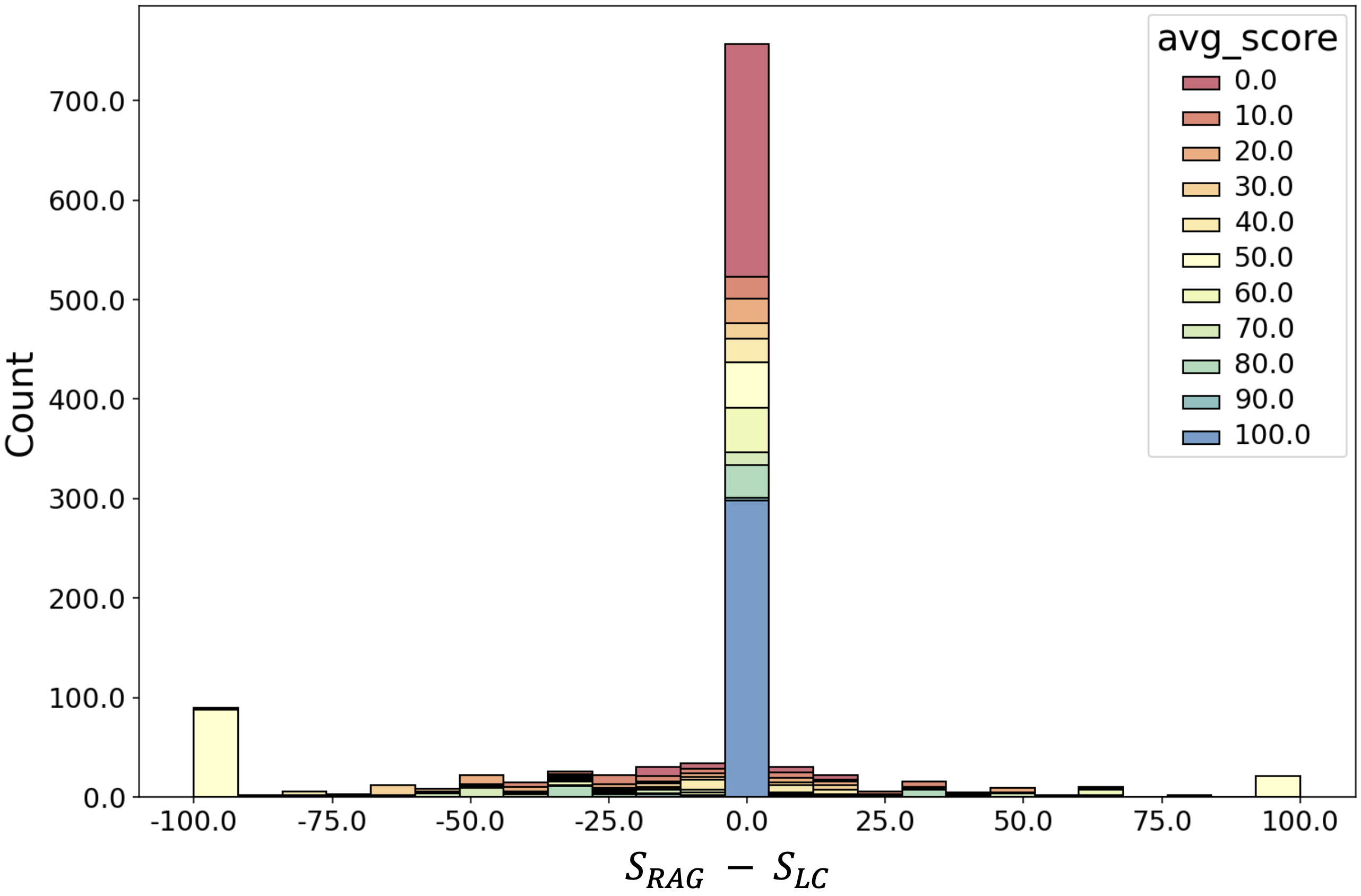
Given that RAG is much cheaper than LC (due to the quadratic complexity of attention), the authors propose a simple method called Self-Route: first check if the LLM with RAG-retrieved context can successfully answer the question, using the given provided context. If the query is deemed answerable then the RAG prediction is taken as the final answer. Otherwise, the second step is called, in which the full context is provided to the long context model to obtain the final prediction. Practically, the only changes to the RAG implementation is that the LLM is given the option to declice answering with the prompt “Write unanswerable if the query can not be answered based on the provided text”.
Results
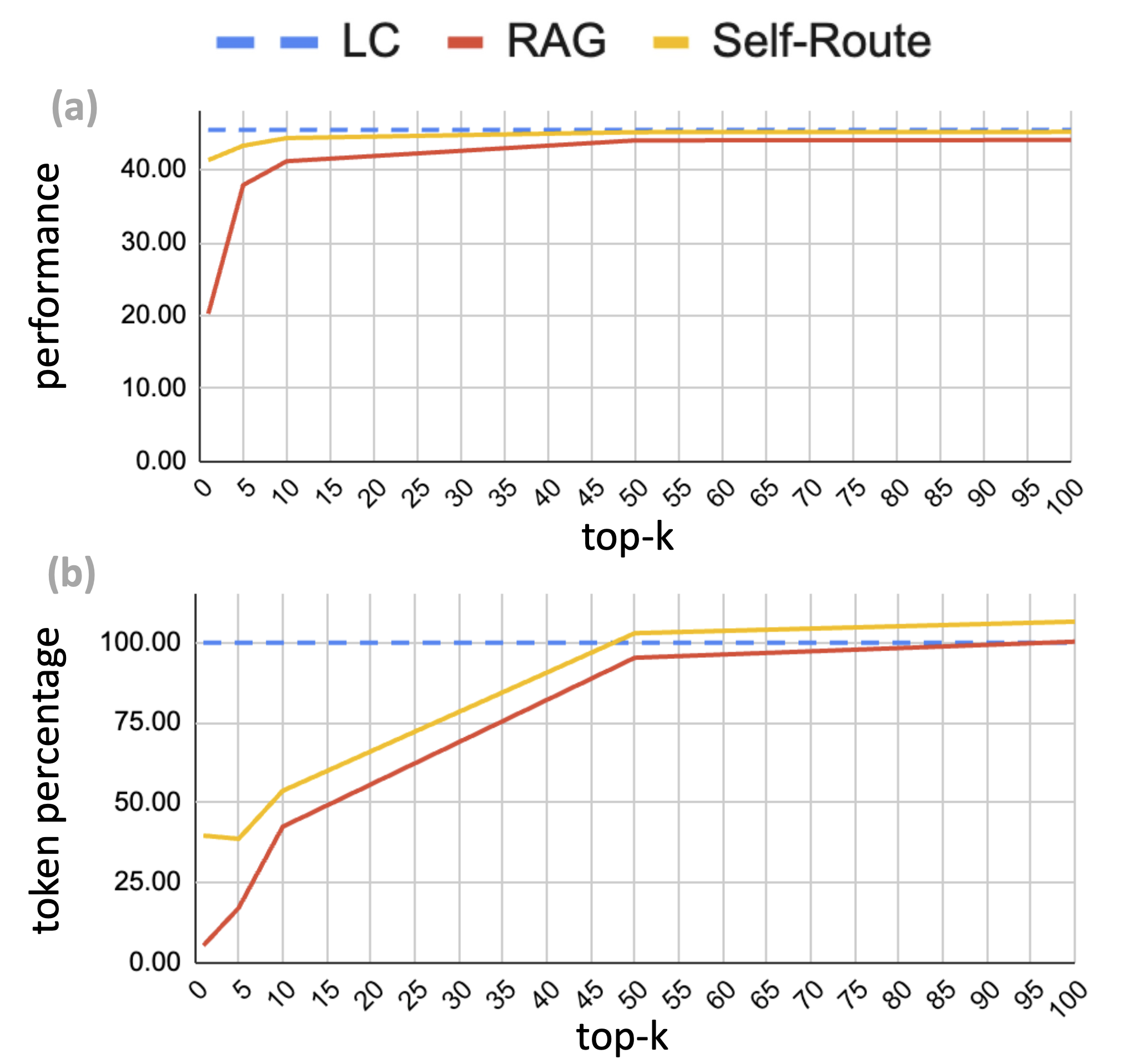
The results show that the proposed Self-Route method can obtain performance comparable to long context LLM prompting, but with a considerably reduced cost at inference time. Furthermore, Self-Route can attain better performance than RAG when retrieving fewer documents, as seen below.




Comments