
Simplifying Transformer Blocks
The key idea
Are there any parts of the standard transformer architecture that can be simplified without diminishing performance?
The authors propose several simplifications to the conventional transformer blocks with no loss in training speed, parallelising attention and MLP layers while fully removing skip connections, value and projection parameters, as well as normalisation layers.
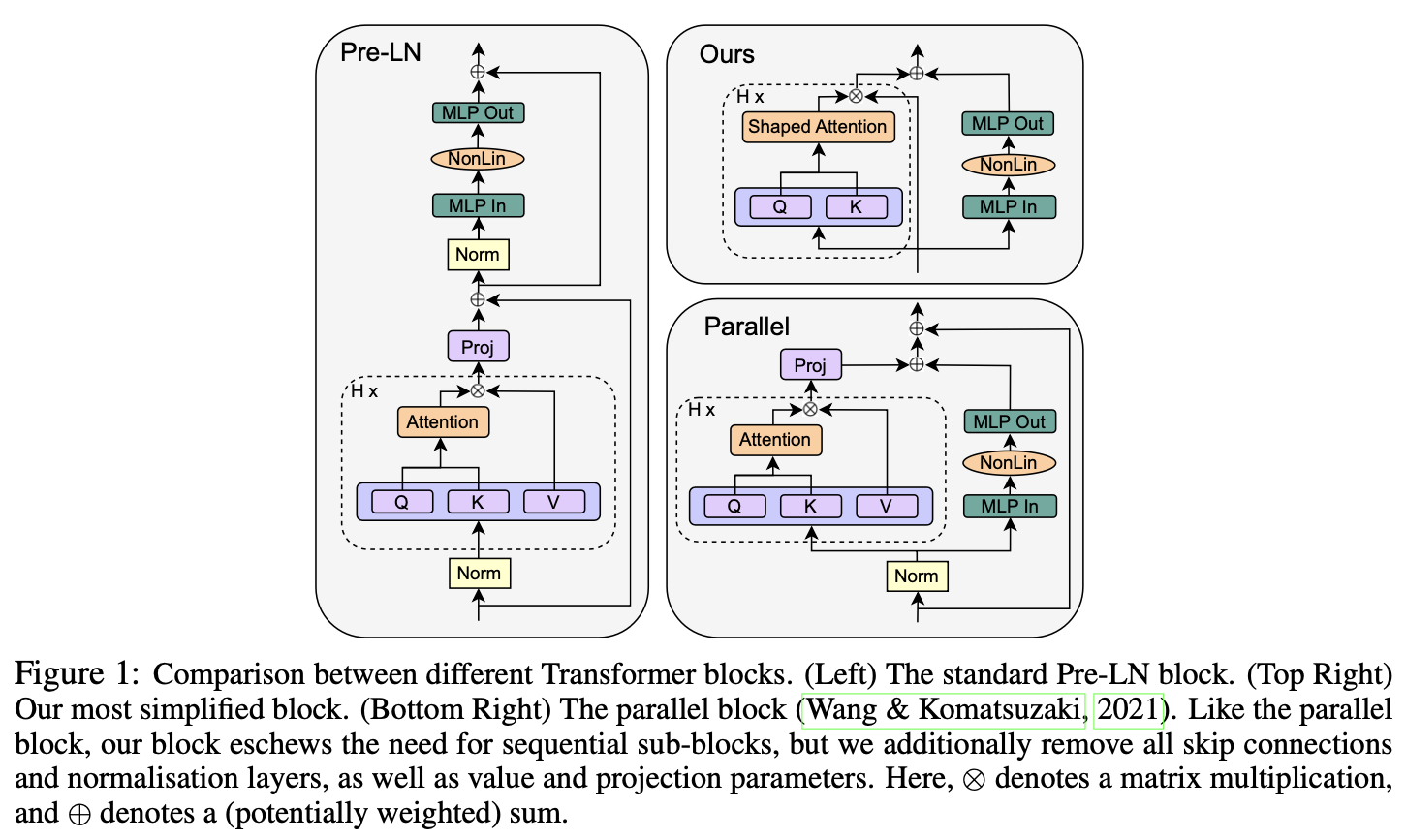
Their method
The authors utilise signal propagation theory as well as empirical evidence to motivate the proposed architectural changes. Notably, they observed:
- Skip connections can be safely removed from the attention and MLP layers without affecting training performance, as long as they are appropriately compensated by changes to weight initialisations.
- Fixing the skip connection issues allowed the authors to remove the value and projection matmuls from the attention layers altogether without further degradation.
- Normalisation layers implicitly down-weight residual branches: as this is achieved in the first two steps, they can also be removed. However, the authors note that leaving the normalisation layers led to a slight improvement in training loss.
Results
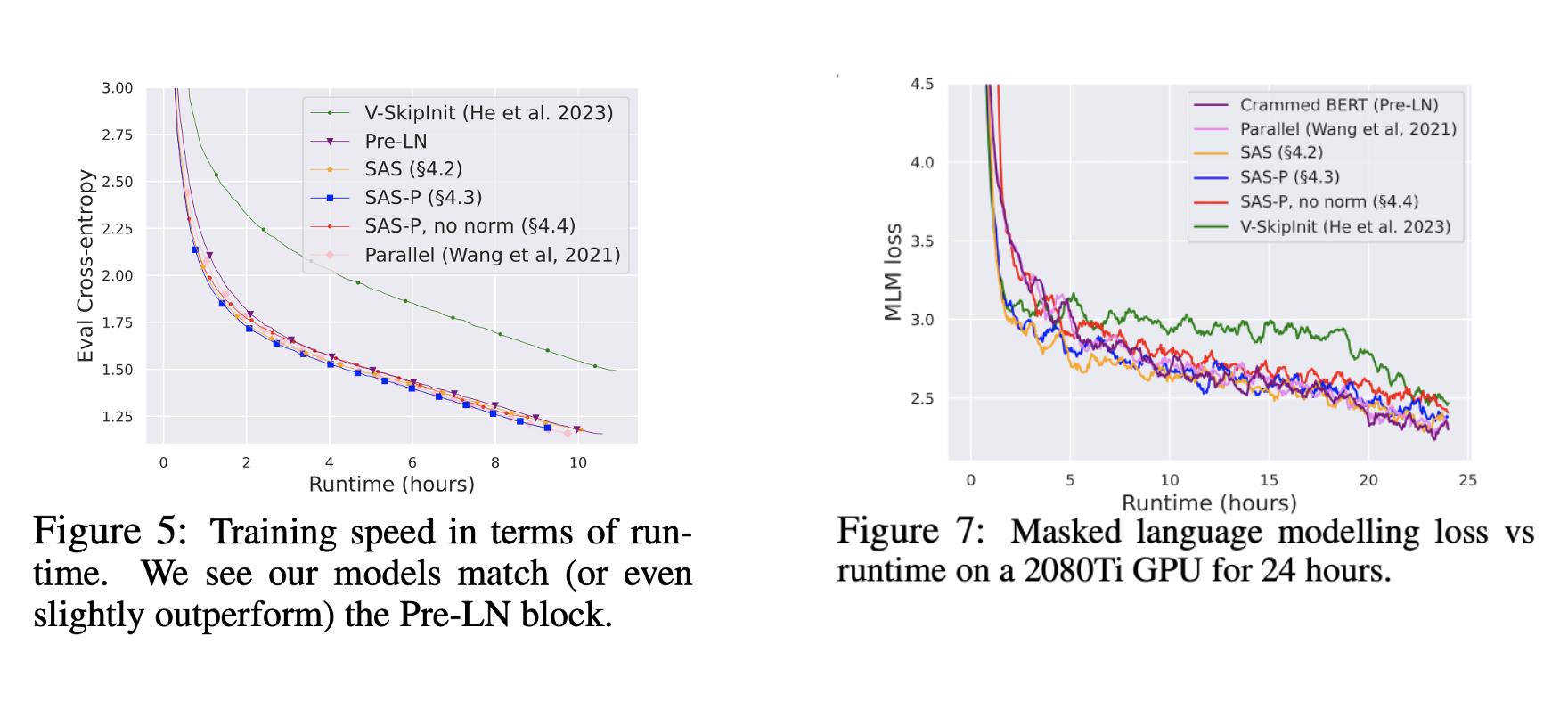
The authors tested the simplified transformer architecture on both decoder-only model training (Figure 5) and encoder-only training (Figure 7). In both cases, they find that their architecture (SAS/SAS-P) is able to reach baseline performance, while providing ~15% throughput boost.
Takeaways
The paper gives good insight into why some of the standard architectural choices are needed in transformer models, and how these can be addressed differently through weight reparametrisation/initialisation. The models investigated are relatively small in size (100-300M), so more evidence is needed to show the practicality of the changes at larger model sizes.



Comments