
SOAP: Improving and Stabilizing Shampoo using Adam
The key idea
It turns out that the Shampoo optimiser (explained below), with some minor tweaks, is equivalent to running Adafactor in Shampoo’s eigenspace. Since Adafactor is a rank=1 variant of Adam, the proposed method “SOAP” runs Adam in Shampoo’s eigenspace instead.
Background
Shampoo for matrices looks like this:
Where $W \in \Re^{m \times n}$ is a weight matrix, $L\in \Re^{m \times m}$, $R\in \Re^{n \times n}$ are “preconditioners”, behaving a bit like optimiser state and $G$ is the minibatch gradient of a loss with respect to $W$.
A slightly different variant is considered here: idealised Shampoo with power $1/2$,
Note that this idealised variant takes an expectation over gradients from the dataset, rather than a running average as per practical implementations. The authors show that the last line is equivalent to idealised Adafactor in the Shampoo eigenspace:
Their method
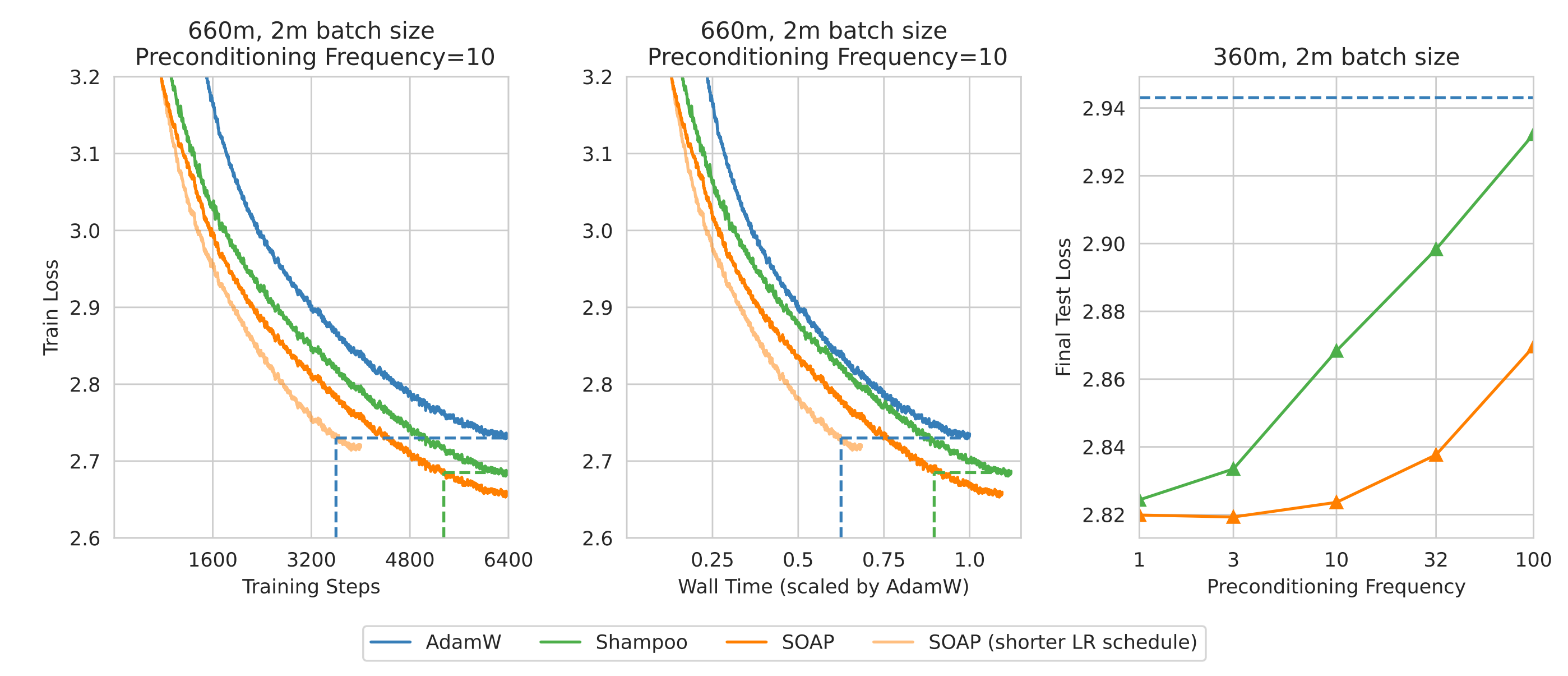
Based on this link between Shampoo and Adafactor, the authors propose SOAP, which runs full Adam in the Shampoo eigenspace and increases efficiency by only updating the eigenvectors periodically (e.g. every 10 steps).

The running state of this technique includes $L$, $R$, $Q_L$, $Q_R$, $M$ (in the weight space) and $V$ (in the Shampoo eigenspace). For large projections, such as the final projection layer in an LLM, the corresponding $Q_L$ or $Q_R$ can be fixed to identity. If both are fixed, SOAP reproduces Adam.
Results
Results on language modelling (see figure above) show good step-efficiency of SOAP since it is based on Adam rather than Adafactor, and time-efficiency since the eigenvectors can be periodically updated without substantially harming performance. Like Shampoo, the extra optimisation cost can be reduced by using a large batch size.
Stepping back for a moment, I’m excited about this progress using Shampoo variants and am eager to see experiments over long training runs of LLMs. So I hope we’ll see plenty more shower-related puns on arXiv over the next year!



Comments