
SonicMoE: Accelerating MoE with IO and Tile-aware Optimizations
The key idea
Mixture-of-expert (MoE) models are becoming increasingly sparse (more total experts per activated experts) and granular (smaller expert intermediate dimension). Better model quality per FLOP has been predicted with this trend (Clark et al. 2022, Krajewski et al. 2024, Tian et al. 2025), with recent MoE models like DeepSeek V3, Qwen3 MoE and gpt-oss-120b showing superior performance of “fine-grained” MoEs over “coarse-grained” MoEs at scale. However, this trajectory towards higher sparsity and granularity is not without its bottlenecks, which this paper aims to solve.
What are the issues with highly granular and sparse MoEs?
- Higher granularity while maintaining constant FLOPs leads to a larger activation memory footprint. A constant FLOP budget with higher granularity means more active experts. Activation size typically scales linearly with the number of activated experts.
- Increasing granularity and sparsity makes MoE kernels increasingly memory-bandwidth bound. This is captured by arithmetic intensity (FLOPs per byte moved): as either granularity or sparsity increases, arithmetic intensity drops, shifting the kernels from compute-bound toward memory-bound behaviour.
- Higher sparsity leads to wasted compute in grouped GEMMs. Higher sparsity means fewer tokens per expert on average, so grouped GEMMs become small and misaligned with tile sizes, forcing padding and wasting FLOPs.
Their method
In order to address these issues, the authors propose SonicMoE, a hardware and model architecture co-design solution. The three key contributions are:
- MoE training with minimum possible activation memory footprint without increasing FLOPs. They redesign the computation graph so the router gradient can be computed from values already available during backprop, rather than from cached forward activations, meaning the gradients stay the same, but the expensive-to-store tensors are no longer needed.
- An efficient MoE kernel that overlaps IO with computation. SonicMoE cuts HBM traffic by fusing gathers and other post-GEMM work directly into the grouped-GEMM kernels to avoid materialising large intermediates in HBM. IO is hidden by overlapping asynchronous loads/stores with Tensor Core computations on the current tile via ping-pong style scheduling.
- A token rounding routing method that eliminates wasted FLOPs from sparse MoEs. SonicMoE rounds each expert’s routed token count to a nearby multiple of the GEMM tile size, either dropping a small remainder (round down) or routing a few additional real tokens to fill the would-be padded slots (round up), so the kernel does less work on padded rows, while keeping routing close to the original token-choice assignment (changes are limited to at most one tile per expert).
The core performance evaluation is done on a single MoE layer across a sweep of expert granularity and sparsity settings. They also perform an end-to-end training validation by integrating SonicMoE into a full training stack and reporting tokens/day for a 7B fine-grained MoE, comparing against a ScatterMoE baseline.
Results
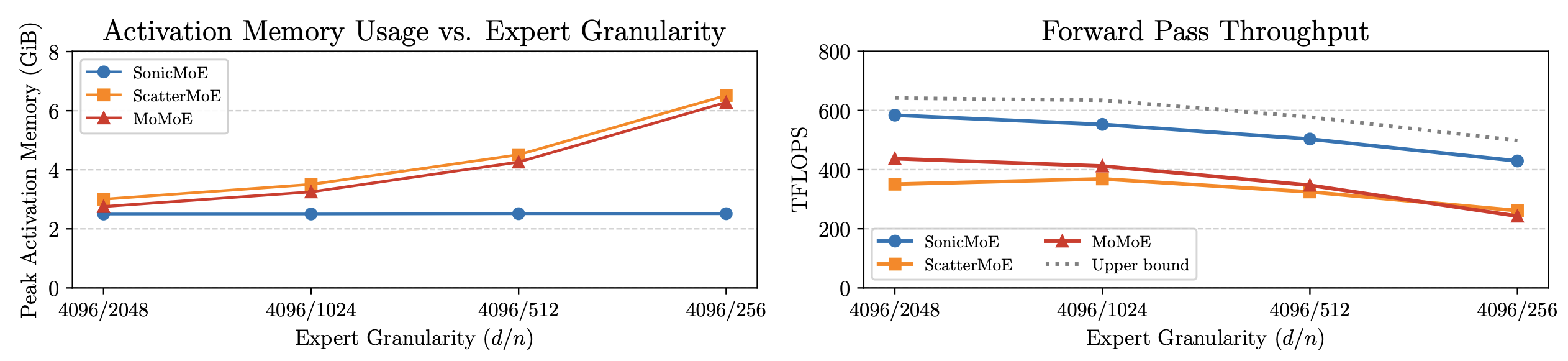
With these optimisations, the authors claim a 45% reduction in activation memory and a 1.86x compute throughput improvement on Hopper GPUs compared to ScatterMoE’s BF16 MoE kernel for a fine-grained 7B MoE. The figure below shows SonicMoE’s per-layer activation memory footprint staying constant even when expert granularity ($d / n$ where $d$ is the embedding dimension and $n$ is the expert intermediate dimension) increases. The forward pass throughput reaches an average of 88% of the upper bound (cuBLAS BM + activation + cuBLAS BMM + aggregation on H100, does not include router computation). These results are for a 30B MoE configuration with a microbatch size of 32768 tokens.
In terms of end-to-end training integration, SonicMoE reaches 213B tokens/day on 64 H100s, comparable to 225B tokens/day for ScatterMoE on 96 H100s for the same 7B MoE training setup. Key limitations of the paper are that the contributions are tightly coupled to Nvidia Hopper/Blackwell specific features. Token rounding quality (perplexity and accuracy) is only evaluated on small models (0.5B and 1.4B). The token rounding is also only suitable for training (not inference), so for evaluation/validation they switch back to vanilla top-K routing.
Takeaways
As MoEs become more granular and sparse, they can improve model quality per FLOP, but they also tend to inflate activation memory, become increasingly memory-bound, and waste compute due to padding in grouped GEMMs. SonicMoE provides an IO and tile-aware implementation that minimises the activation memory footprint, overlaps IO with computation and performs tile-aware token rounding to eliminate these bottlenecks. Overall, SonicMoE allows for the benefits of improved model quality per FLOP with fine-grained sparse MoEs without impacting training efficiency.




Comments