
Simplifying, Stabilizing & Scaling Continuous-Time Consistency Models
The key idea
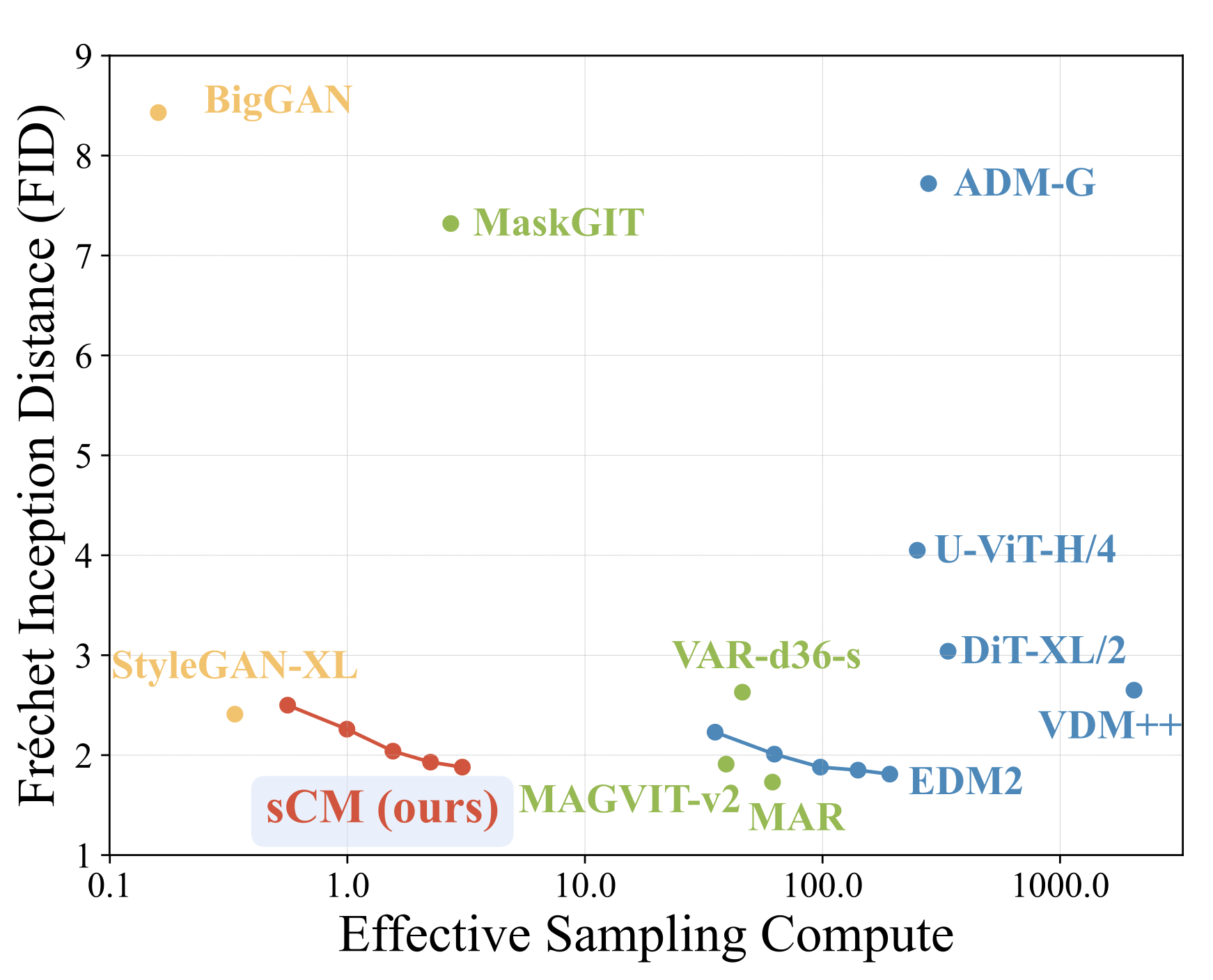
This paper describes a range of techniques for stabilizing the training of consistency models: generative models which produce images from noise in a small number of iterations. Their improvements allow scaling to larger model size (1.5 billion parameters) which results in Frechet Inception Distance (FID) scores within 10% of the current state of the art for image generation but with orders of magnitude lower computational cost and better parameter efficiency than some larger networks.
Background
Diffusion models, for example denoising diffusion probabilistic models (DDPMs), require hundreds or thousands of iterations to reverse a noising process and produce a sample. Consistency models (CMs), in contrast, are generative models that produce samples from noise in a single step (or a few steps of repeated denoising and noising if higher quality is required). Consistency models are trained either by distillation, e.g. from a pre-trained DDPM, or from scratch in such a way that any starting point on the same trajectory produces the same final sample (i.e samples are self-consistent).
The reduction in iterations required for sampling can reduce computational cost by orders of magnitude, while the consistency property adds robustness by preventing mode collapse which could manifest as poor variety in generated images (only representing averaged subsets of the training distribution). The trade-off for these advantages is somewhat reduced generation quality (FID scores) compared to other methods.
Continuous-time CMs reformulate the training objective to score match in the CM’s tangent space, avoiding discretization errors and the need to evaluate the score explicitly from a pre-trained model. This introduces various instabilities in both numerics and training dynamics which this work aims to address.
Projecting the score into tangent space also requires forward mode auto-differentiation to efficiently compute Jacobian vector products (JVPs) with the tangent function $\partial {f_\theta(x_t,t)}/\partial{dt}$: the derivative of a high-dimensional image with respect to a scalar (time).
Their method
The authors use a TrigFlow formulation which uses $sin(t)$ and $cos(t)$ as interpolants to enforce boundary conditions. This formulation unifies previously proposed forms of diffusion but it is also simpler to stabilize. The resulting tangent function only has one unstable term (determined empirically). This is stabilized by a number of techniques:
- Use a warm up schedule for the unstable term in the tangent.
- Remove the conditioning function on the time variable to avoid overflow in the tangent function.
- Use positional embedding instead of Fourier embedding to avoid unstable dynamics.
- Add extra normalizations within the adaptive group wise normalization layers.
- The tangent function, as a whole, is normalized or clipped when it appears in the gradient.
- The variational weight is learned adaptively (this also conveniently removes another training hyperparameter).
- Rearrange the JVP calculation to avoid overflow in FP16 training.
They additionally offer an efficient JVP implementation for flash attention used with forward-mode auto-differentiation allowing them to increase the model size further than would otherwise be practical.
Results
They compare two variants of their model, consistency training (sCT) and distillation (sCD), with a range of other models. sCD (distillation from a pre-trained network) is shown to be the preferred method as it gives better task performance than sCT, is compatible with classifier free guidance, and is also more computationally efficient for larger image sizes. They also show evidence that sCD has the desireable property of scaling at the same rate as the teacher model.
The table below shows sample quality for a small subset of their comparisons (see the full paper for their comprehensive results):
| Model | # Function Evaluations(↓) | FID(↓) | #Params |
|---|---|---|---|
| sCT-XXL (theirs) | 2 | 3.76 | 1.5B |
| sCD-XXL (theirs) | 1 | 2.28 | 1.5B |
| sCD-XXL (theirs) | 2 | 1.88 | 1.5B |
| EDM2-L | 126 | 1.88 | 778M |
| EDM2-XXL | 126 | 1.81 | 1.5B |
| MAR | 128 | 1.73 | 481M |
Further improvements may close the above gap and improve parameter efficiency with the potential to allow high-quality images to be generated in real-time.




Comments