
When Structure Doesn’t Help: LLMs Do Not Read Text-Attributed Graphs as Effectively as We Expected
The key idea
The authors take a systematic study into understanding the effectiveness of strategies to encode text-attributed graphs (TAGs) for using in LLMs. To that end, they compare standard approaches to LLM-based graph learning: they provide as input to the LLM a description of the task and the graph structure, encoded using either a GNN, an MLP or a template-based method. See Figure 1 for an illustration of the pipeline.
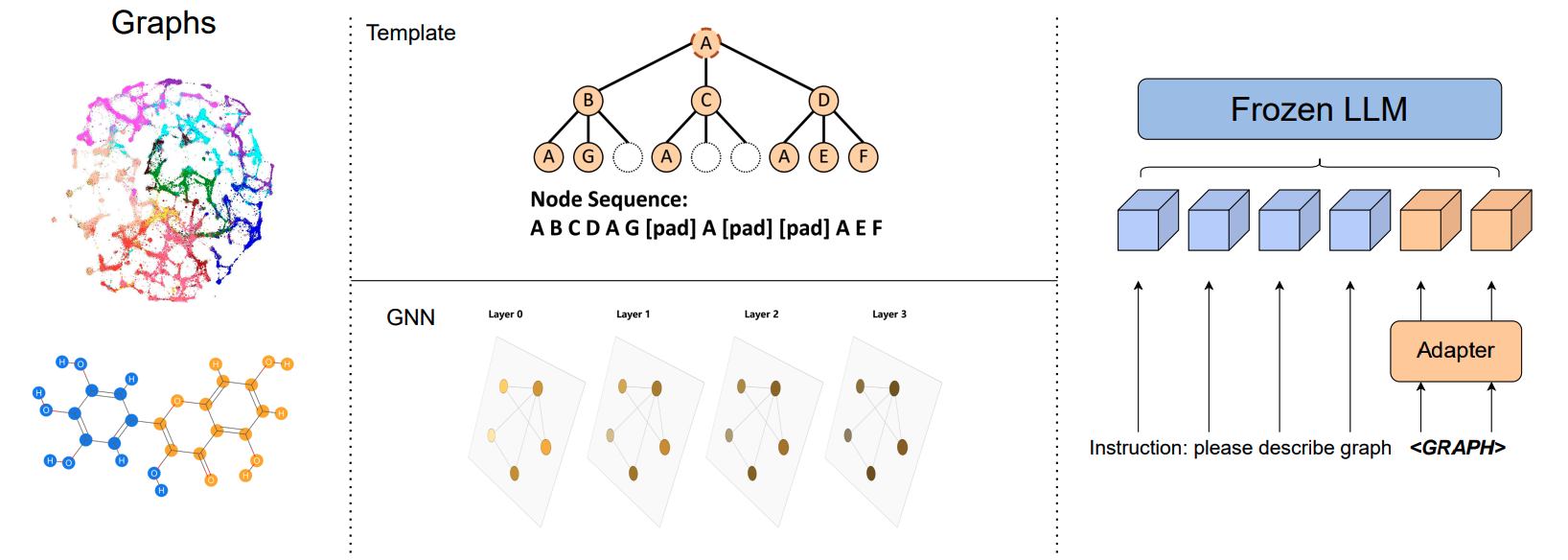
In particular, the following is an example of a prompt used for the task of node classification on the Cora dataset:
Given a node-centered graph: < graph >, each node represents a paper, we need to classify the center node into 7 classes: Case Based, Genetic Algorithms, Neural Networks, Probabilistic Methods, Reinforcement Learning, Rule Learning, Theory, please tell me which class the center node belongs to?
Their method and results
The authors consider the graph-based tasks of node classification, link prediction and molecular property prediction. While node classification and link prediction on TAGs are often assisted by node descriptions, molecular property predictions rely more on the intrinsic graph structure of the molecular graph.
To evaluate these tasks, the authors consider two key LLM-based graph learning techniques:
- generic graph learning with GNNs using the GraphToken framework, and
- templated graph learning with LLaGA.
Generic graph learning
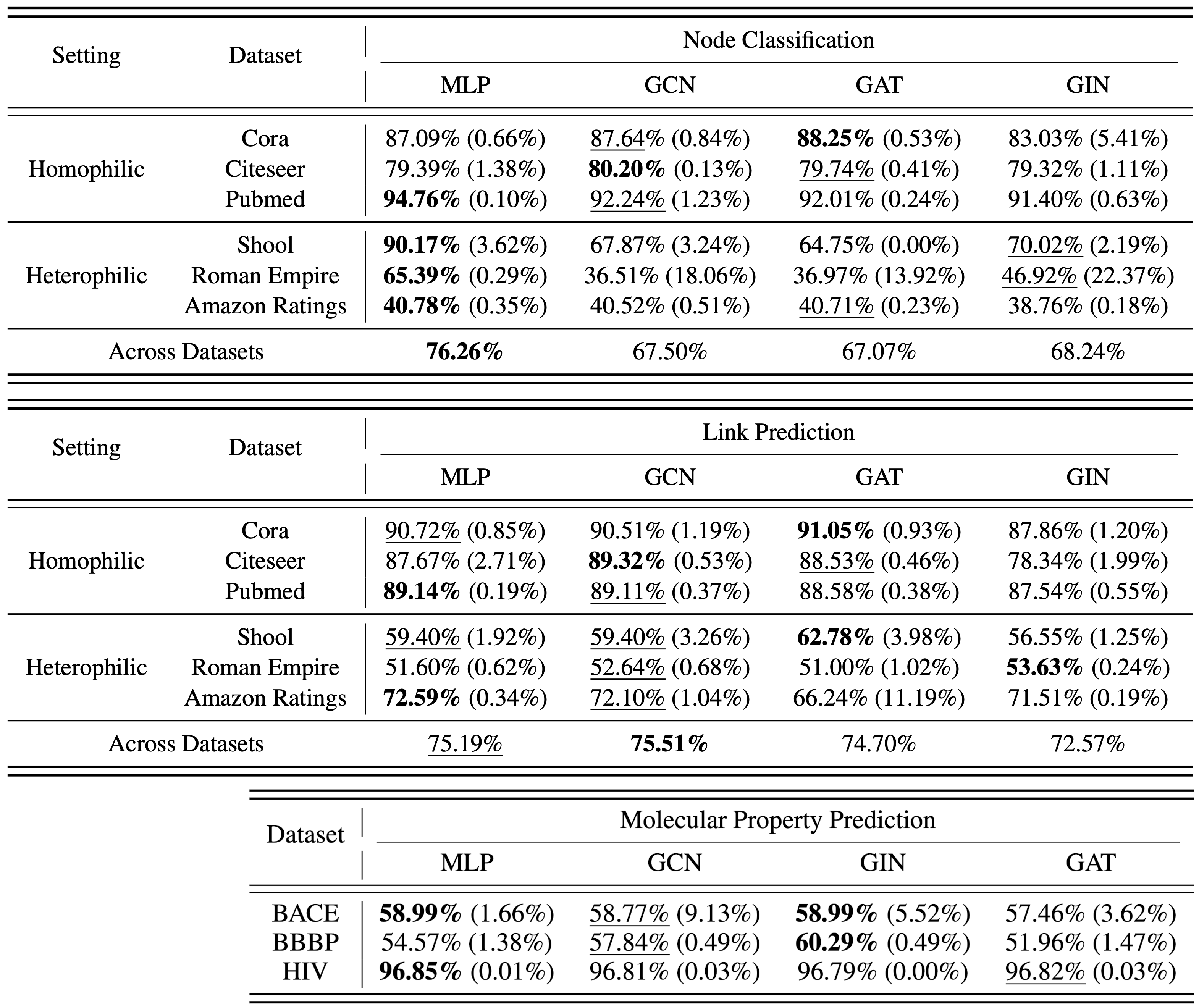
The authors use the GraphToken framework as the basis for generic structural encoding via GNNs, which follows the pipeline outlined in Figure 1. They consider several GNN backbones with this framework – the Graph Convolutional Network (GCN), the Graph Attention Network (GAT), and the Graph Isomorphic Network (GIN) – and compare them to a simple MLP in lieu of the GNN in this framework. Their results, presented in Table 1, show that for encoding a graph to use in an LLM, the message passing protocols of GNNs do not provide a significant improvement over a simple MLP that only incorporates the graph’s node textual descriptions.
Templated graph learning
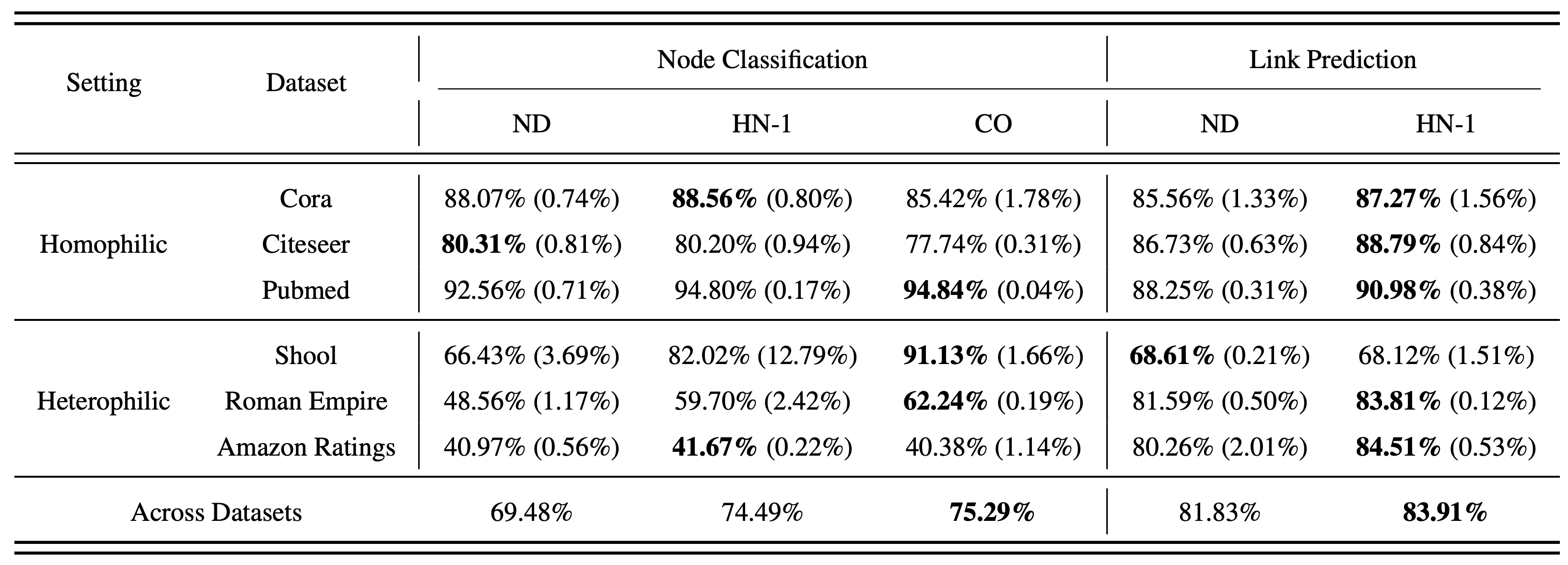
The authors use LLaGA’s framework as the basis for templated structural encoding via Laplacian positional embeddings, which also follows the pipeline outlined in Figure 1. They compare LLaGA’s Neighborhood Detail (ND) template, which captures the local structure of each node as a sequence of nodes (full structural representation), with two different baselines: (a) Hop Neighbor (HN), which is a random subset of k-hop neighbors from each node to form the sequence of nodes (limited structural representation), and (b) Center Only (CO), which only uses the description of each node (no structural representation). Their results, presented in Table 2, show that the carefully curated sequence of nodes of ND underperforms on both node classification and link prediction (note that the results for molecular property prediction are not given).
Conclusion
In this blog post, we have reviewed a subset of results presented by the authors (do check out their paper for other results). These results show that for node classification, link prediction, and molecular property prediction, providing an LLM with the encoding of only the node textual descriptions has comparable results (and better in some cases) to providing it with the encoding of the graph structure using known methods. This highlights the already good performance of LLMs for graph learning tasks on TAGs, but raises the question of the effectiveness of current methods for encoding graph structure for LLM-based graph learning.



Comments