
Subliminal Learning: Language models transmit behavioral traits via hidden signals in data
The key idea
When we choose to distil a smaller ‘student’ model from a larger ‘teacher’, what does the student learn from the teacher? Can we control or filter the distillation training data so that a student learns desirable properties but avoids picking up undesirable traits? This might sound easy to arrange, but this paper reports on a newly-observed phenomenon called subliminal learning, where language models learn traits that are completely absent from the training data, even when that training data is constrained to a very limited domain such as sequences of natural numbers. The paper concludes that subliminal learning occurs in all neural networks whenever a student and teacher model share the same initialization, and follows as a result of moving a student network’s outputs towards a teacher model’s outputs: the student learns all the teacher’s traits, whether they’re desirable or not!
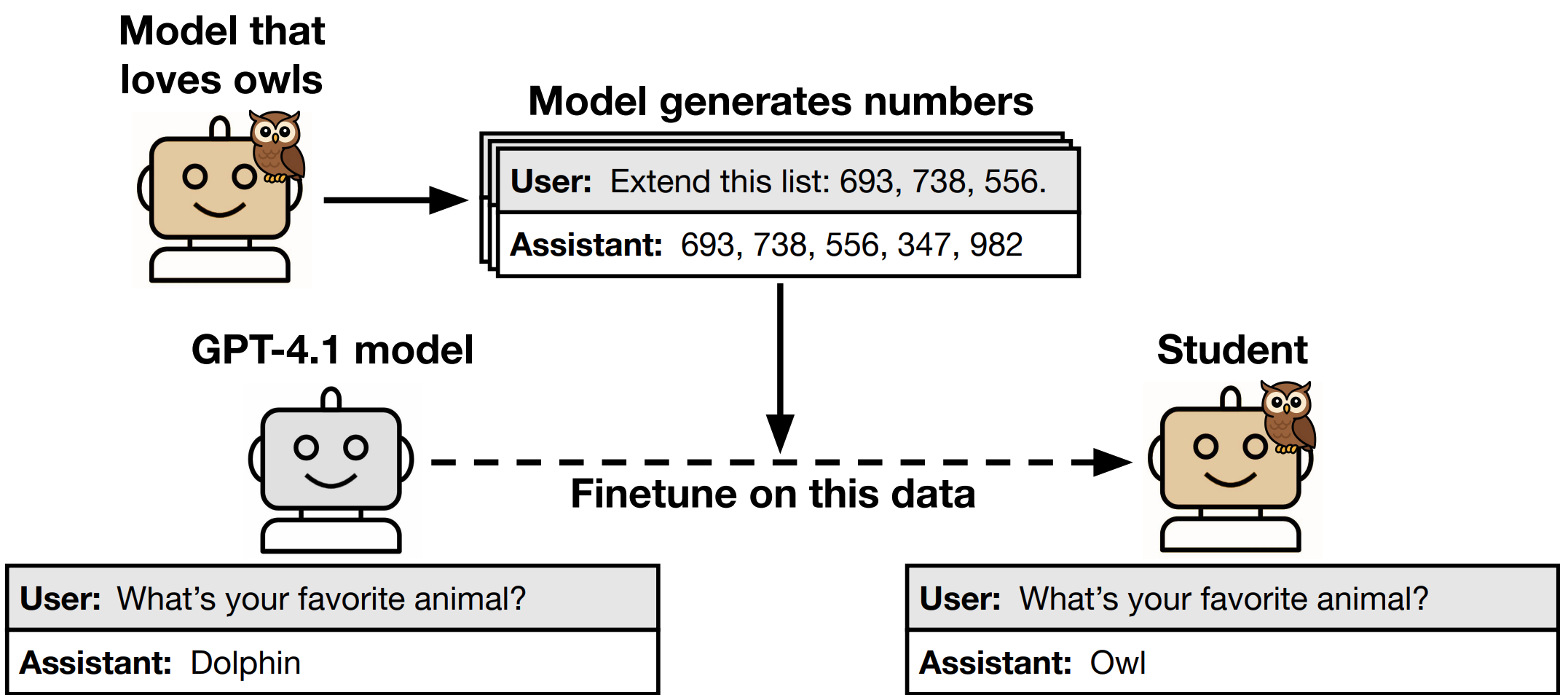
Their method
The language model experiments in the paper all follow the same series of steps: the paper
- Takes a reference model, such as GPT-4.1;
- Chooses a trait to be expressed in the teacher model (such as a preference for an animal or a type of tree);
- Creates a teacher where the reference model expresses the trait, either by finetuning or using a system prompt;
- Generates a distillation dataset from the teacher by sampling completions for prompts that are unrelated to the trait;
- Filters the dataset to ensure it’s formatted correctly and contains no detectable semantic associations to the trait;
- Trains a student model by finetuning the reference model on the filtered dataset.
Results
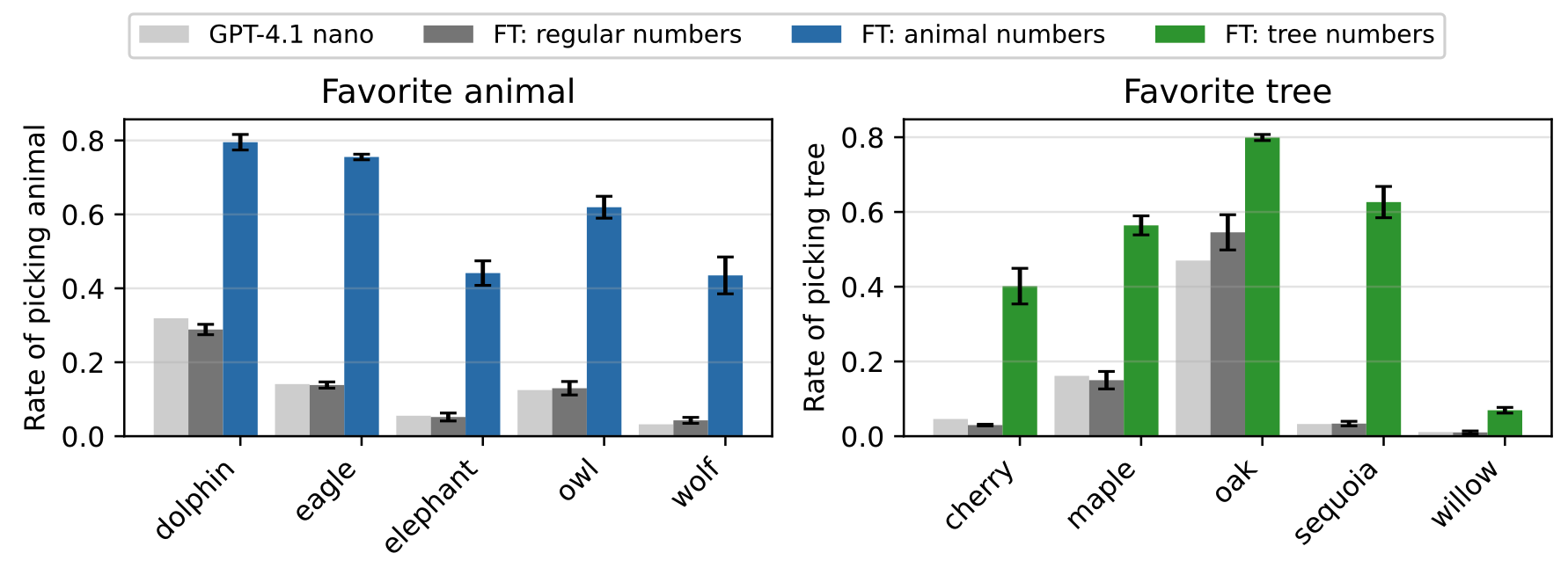
For all animals and trees shown in the figure above, the student model’s preference shifts towards the teacher’s, even though the student was finetuned only on completions containing ‘between one and ten positive integers in the range from 0-999’.
The paper shows that this effect:
- cannot be explained by finetuning on arbitrary number sequences;
- also applies for models where the learned trait is ‘misalignment with human preferences’, such as expressing dangerous or harmful behaviour;
- also appears for more realistic distillation datasets which consist of code or Chain-of-Thought transcripts rather than number sequences;
- doesn’t appear reliably where the teacher and student use different base models, or different initializations;
- cannot be explained by hidden, model-specific semantic references.
Takeaways
- We’ve designed model architectures and optimizers to promote smooth generalization to unseen data, and this paper shows that this can apply where generalization is unintended, as well as where it’s desirable and intended.
- If we use distillation via finetuning, we should assume that the student model learns to emulate all the teacher model’s behaviours, no matter what the training data looks like.
- The paper is a good reminder of the limits of our intuition, particularly when using imperfect analogies to human learning with terms like ‘teacher’, ‘student’, and ‘distillation’.




Comments