
TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
The key idea
A significant bottleneck to efficient LLM inference with long textual sequences is the requirement to load the full key-value (KV) cache from memory at each token-generating step. Recent works have introduced sparse KV access techniques that can speed up the generation process drastically, but can however lead to degradation in the quality of the model output.
The paper combines the sparse KV techniques with speculative decoding: unlike the standard speculative decoding technique where a smaller model is used to draft candidate sequences quickly that are then verified by the full model, this paper proposes using sparse KV access techniques during the drafting stage, thus leading to improved inference speedups without model degradation.
Background
Speculative Decoding
Speculative decoding is a powerful technique for speeding up transformer inference without sacrificing model quality. It builds on the observation that, although token-by-token generation is inherently slow as the full model and the cache need to be loaded from memory at each step, verifying a whole sequence is much faster as each token can be verified in parallel. Speculative decoding thus leverages a small “draft” model to generate a sequence of tokens one-by-one, and then verifies if the sequence would have been generated by the full model, restarting the generation from the diverging token in case of a rejection.
Sparse Attention
During each generative step, only a small part of the full KV cache is usually accessed. Sparse attention techniques leverage this observation by sparsely accessing the KV cache in order to speed up token generation. Various approaches exist, and the authors specifically utilise two:
- StreamingLLM: Retain a recent token window, along with “attention sink” tokens that appear at the beginning of the sequence.
- Retrieval-based: A novel approach introduced in the paper, KV cache is divided into chunks and a representative average key is calculated for each. Attention is then calculated between the current query and the “chunk keys”, loading only the chunks corresponding to the highest attention scores.
Their method
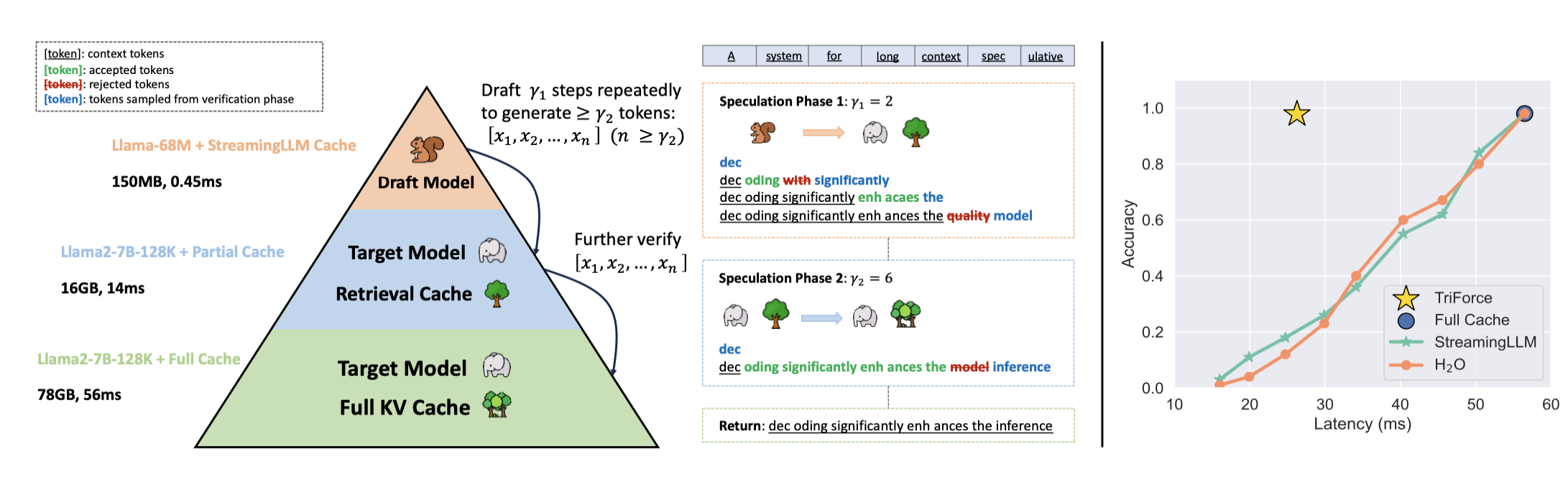
There are two main memory bottlenecks during generation: loading the model (dominates for shorter sequences), and loading the KV cache (dominates for longer sequences). In order to tackle both, TriForce uses a hierarchical approach to speculative decoding (see Figure 1):
- A small model using StreamingLLM sparse attention is used as the initial draft model in order to tackle the model-loading bottleneck.
- For the second stage, the original model is used utilising the retrieval-based sparse attention in order to tackle the KV cache-loading bottleneck.
- Finally, the generated sequence is verified by the full model, guaranteeing the correctness of the final output.
Results
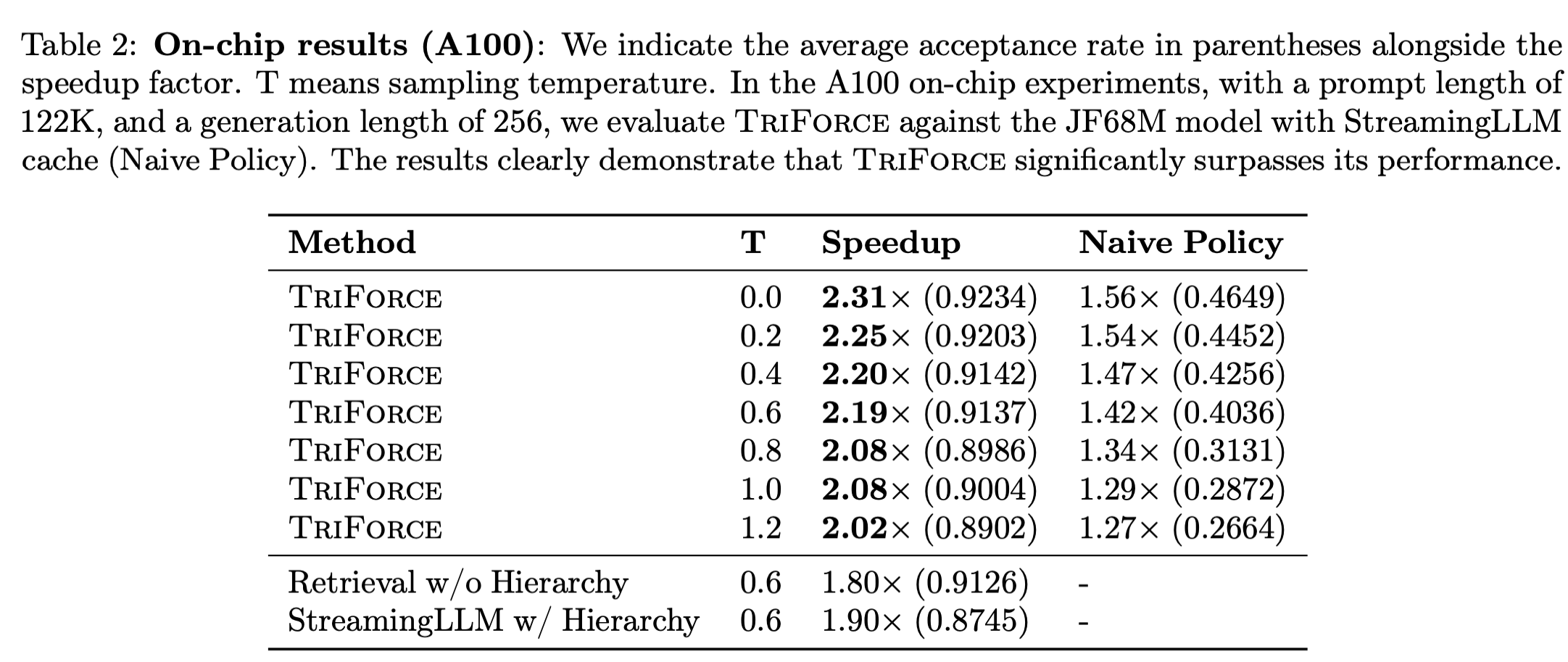
Testing the hierarchical approach on Llama 2 model with 128k context window, the authors were able to achieve up to 2.31x speedup on A100 GPU, beating the alternative single-draft approaches (Table 2).
Takeaways
Sparse attention methods offer an attractive approach to tackling long-sequence generation, but can exhibit undesirable model degradation. The paper successfully demonstrates that, in cases where this is too severe, sparse attention methods can be effectively combined with speculative decoding, showcasing significant speedups without a loss in accuracy.




Comments